This is a quick note to myself, so I remember the best way to protect PDFs behind a password on a course blog. Joe Ugoretz highlights the problems with most methods, and then proposes the solution I’m using here: Ben Balter’s WP Document Revisions plugin. There are a few tricks involved to get WP Document Revisions up and running on a WordPress multisite installation. Here’s what works for me: Continue reading “Password Protecting PDFs on Course Blogs”
Author: Mark Sample
“Warning: Infected inside, do not enter”
Zombies and the Liberal Arts
On Saturday, April 18, I gave the following talk at Bard College, as part of Bard’s Experimental Humanities Mellon lecture series. Sorry if it doesn’t read as an “academic” talk. It’s written to be told.
I’m going to tell you a story today about zombies and the liberal arts. There are a lot of places I could begin—say, the huge number of classes in the humanities that focus on zombies, or the burgeoning field of zombie scholarship. But I’m going to take a more circuitous route, a kind of lurching, shambling path to connect the dots. The story begins in 2013. That’s the year the film adaptation of Max Brook’s World War Z came out. It’s the year The Last of Us became a bestselling game for the Sony Playstation. It’s also the year Pat McCrory, the North Carolina Governor—my home state governor—was a guest on Bill Bennett’s radio talk show to talk about his vision for the North Carolina public university system. Chapel Hill. NC State. UNC-Charlotte. McCrory told Bennett—who, if your memory goes back that far, was Reagan’s Secretary of Education, he told Bennett that “If you want to take gender studies that’s fine, go to a private school and take it. But I don’t want to subsidize that if that’s not going to get someone a job.”1 Continue reading ““Warning: Infected inside, do not enter”
Zombies and the Liberal Arts“
Kevin Kiley. “North Carolina Governor Joins Chorus of Republicans Critical of Liberal Arts.” Inside Higher Ed, January 30, 2013. https://www.insidehighered.com/news/2013/01/30/north-carolina-governor-joins-chorus-republicans-critical-liberal-arts.↩
“Deep” Textual Hacks
A computational and pedagogical workshop
I put “deep” in scare quotes but really, all three words should have quotes around them—”deep” “textual” “hacks”—because all three are contested, unstable terms. The workshop is hands-on, but I imagine we’ll have a chance to talk about the more theoretical concerns of hacking texts. The workshop is inspired by an assignment from my Hacking, Remixing, and Design class at Davidson, where I challenge students to create works of literary deformance that are complex, intense, connected, and shareable. (Hey, look, more contested terms! Or at the very least, ambiguous terms.)
We don’t have much time for this workshop. In this kind of constrained setting I’ve found it helps to begin with templates, rather than creating something from scratch. I’ve also decided we’ll steer clear of Python—what I’ve been using recently for my own literary deformances—and work instead in the browser. That means Javascript. Say what you want about Javascript but you can’t deny that Daniel Howe’s RiTA library is a powerful tool for algorithmic literary play. But we don’t even need RiTA for our first “hack”:
- Taroko Gorge (2009) by Nick Montfort
What’s great about “Taroko Gorge” is how easy it is to hack. Dozens have done it, including me. All you need is a browser and a text editor. Nick never explicitly released the code of “Taroko Gorge” under a free software license, but it’s readily available to anyone who views the HTML source of the poem’s web page. Lean and elegantly coded, with self-evident algorithms and a clearly demarcated word list, the endless poem lends itself to reappropriation. Simply altering the word list (the paradigmatic axis) creates an entirely different randomly generated poem, while the underlying sentence structure (the syntagmatic axis) remains the same.
The next textual hack template we’ll work with is my own:
This little generator is essentially half of @_LostBuoy_. It generates Markov chains from a source text, in this case, Moby-Dick. What’s a Markov chain? It’s a probabilistic chain of n-grams, that is, words. The algorithm examines a source text and figures out which word or words are likely to follow another word or other words. The “n” in n-gram refers to the number of words you want the algorithm to look for. For example, a bi-gram Markov chain calculates which pair of words are likely to follow another pair of words. Using this technique, you can string together sentences, paragraphs, or entire novels. The higher the “n” the more likely the output is to resemble the source material—and by extension, sensible English. Whereas “Taroko Gorge” plays with the paradigmatic axis (substitution), Markov chains play along the syntagmatic axis (sentence structure). There are various ways to calculate Markov chains; creating a Markov chain generator is even a common Intro to Computer Science assignment. I didn’t build my own generator, and you don’t have to either. I use RiTA, a Javascript (and Processing) library that works in the browser, with helpful documentation.
The final deformance is a web-based version of the popular @JustToSayBot:
- Just To Say (web version) (source plus also grab RiTA again and JQuery)
And I have a challenge here: thanks to the 140-character limit of Twitter, the bot version of this poem is missing the middle verse. The web has no such limit, of course, so nothing is stopping workshop participants from adding the missing verse. Such a restorative act of hacking would be, in a sense, a de-deformance, that is, making my original deformance less deformative, more like the original.
Digital Humanities at MLA 2015
Vancouver, January 8-10
Here is a list of more or less digitally-oriented sessions at the upcoming Modern Language Association convention. These sessions address digital culture, digital tools, and digital methodology, played out across the domains of research, pedagogy, and scholarly communication. If I’ve overlooked a session, let me know in the comments. You might also be interested in my short reflection on how the 2015 program stacks up against previous MLA programs. Continue reading “Digital Humanities at MLA 2015
Vancouver, January 8-10“
Digital Humanities and the MLA
On the state of the field at the MLA
Since 2009 I’ve been compiling an annual list of more or less digitally-oriented sessions at the Modern Language Association convention. This is the list for 2015. These sessions address digital culture, digital tools, and digital methodology, played out across the domains of research, teaching, and scholarly communication. For the purposes of my annual lists I clump these varied approaches and objects of study into a single contested term, the digital humanities (DH).
DH sessions at the 2015 convention make up 7 percent of overall sessions, down from a 9 percent high last year. Here’s what the trend looks like over the past 6 MLA conventions (there was no convention in 2010, the year the conference switched from late December to early January): Continue reading “Digital Humanities and the MLA
On the state of the field at the MLA“
Closed Bots and Green Bots
Two Archetypes of Computational Media
The Electronic Literature Organization’s annual conference was last week in Milwaukee. I hated to miss it, but I hated even more the idea of missing my kids’ last days of school here in Madrid, where we’ve been since January.
If I had been at the ELO conference, I’d have no doubt talked about bots. I thought I already said everything I had to say about these small autonomous programs that generate text and images on social media, but like a bot, I just can’t stop.
Here, then, is one more modest attempt to theorize bots—and by extension other forms of computational media. The tl;dr version is that there are two archetypes of bots: closed bots and green bots. And each of these archetypes comes with an array of associated characteristics that deepen our understanding of digital media. Continue reading “Closed Bots and Green Bots
Two Archetypes of Computational Media“
Difficult Thinking about the Digital Humanities
Five years ago in this space I attempted what I saw as a meaningful formulation of critical thinking—as opposed to the more vapid definitions you tend to come across in higher education. Critical thinking, I wrote, “stands in opposition to facile thinking. Critical thinking is difficult thinking. Critical thinking is being comfortable with difficulty.”
Two hallmarks of difficult thinking are imagining the world from multiple perspectives and wrestling with conflicting evidence about the world. Difficult thinking faces these ambiguities head-on and even preserves them, while facile thinking strives to eliminate complexity—both the complexity of different points of view and the complexity of inconvenient facts. Continue reading “Difficult Thinking about the Digital Humanities”
DIG 210: Data Culture
A new course for the Digital Studies program at Davidson College. Influences for the syllabus abound: Lisa Gitelman, Lauren Klein, Ben Schmidt, Matt Wilkens, and many other folks in the digital humanities.
Course Description
“Data” is often considered to be the domain of scientists and statisticians. But with the proliferation of databases across nearly all aspects of modern life, data has become an everyday concern. Bank accounts, FaceTime records, Snapchat posts, Xbox leaderboards, CatCard purchases, your DNA—at the heart of all them is data. To live today is to breathe and exhale data, wherever you go, online and off. And at the same time data has become a function of daily life, it has also become the subject of—and vehicle for—literary and artistic critiques.
This course explores the role of data and databases in contemporary culture, with an eye toward understanding how data shapes the way we perceive—and misperceive—the world. After historicizing the origins of modern databases in 19th century industrialization and census efforts, we will survey our present-day data landscape, considering data mining, data visualization, and database art. We will encounter nearly evangelical enthusiasm for “Big Data” but also rigorous criticisms of what we might call naïve empiricism. The ethical considerations of data collection and analysis will be at the forefront of our conversation, as will be issues surrounding privacy and surveillance. Continue reading “DIG 210: Data Culture”
Sites of Pain and Telling

The Expressive Work of Spaces of Torture in Videogames
At the 2014 MLA conference in Chicago I appeared on a panel called “Torture and Popular Culture.” I used the occasion to revisit a topic I had written about several years earlier—representations of torture-interrogation in videogames. My comments are suggestive more than conclusive, and I am looking forward to developing these ideas further.
Today I want to talk about spaces of torture—dungeons, labs, prisons—in contemporary videogames and explore the way these spaces are not simply gruesome narrative backdrops but are key expressive features in popular culture’s ongoing reckoning with modern torture. Continue reading “Sites of Pain and Telling”
History and Future of the Book (Fall 2014 Digital Studies Course)

A tentative syllabus for DIG 350: History & Future of the Book, a course just approved for the Digital Studies program at my new academic home, Davidson College. Many thanks to Ryan Cordell, Lisa Gitelman, Kari Kraus, Jessica Pressman, Peter Stallybrass, and many others, whose research and classes inspired this one.
DIG 350: History & Future of the Book
Course Description
A book may only be made of paper, cardboard, ink, and glue, but it is nonetheless a remarkable piece of technology—about which we have mostly forgotten it is a piece of technology. This class is concerned with the long history, the varied present, and the uncertain future of the book in the digital age. Continue reading “History and Future of the Book (Fall 2014 Digital Studies Course)”
What crisis in the humanities? Interactive Historical Data on College Majors
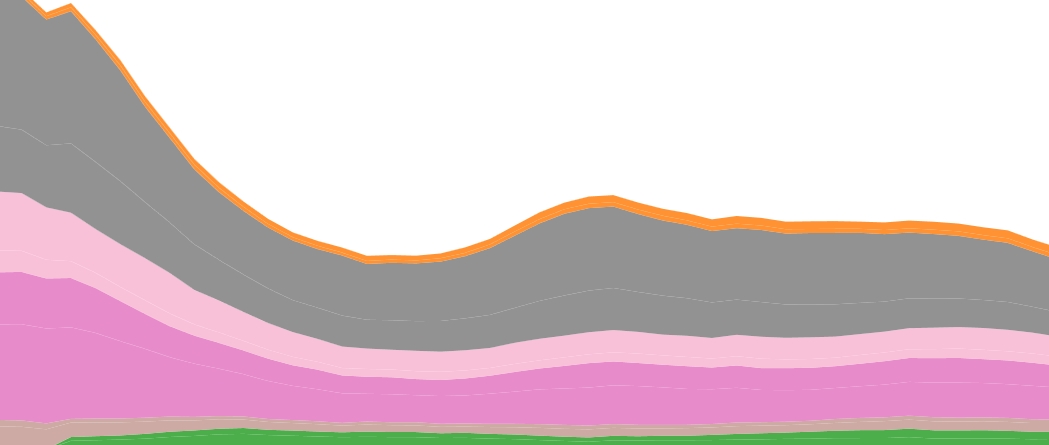
If you’re an academic, you’ve probably heard about the recent New York Times article covering the decline of humanity majors at places like Stanford and Harvard. As many people have already pointed out, the article is a brilliant example of cherry-picking anecdotal evidence to support an existing narrative (i.e. the crisis in the humanities)—instead of using, you know, actual facts and statistics to understand what’s going on.
Ben Schmidt, a specialist in intellectual history at Northeastern University, has put together an interactive graph of college majors over the past few decades, using the best available government data. Playing around with the data shows some surprises that counter the prevailing narrative about the humanities. For example, Computer Science majors have declined since 1986, while History has remained steady. Ben argues elsewhere that not only was the steepest decline in the humanities in the 1970s instead of the 2010s, but that the baseline year that most crisis narratives begin with (the peak year of 1967) was itself an aberration.
Of course, Ben’s data is in the aggregate and doesn’t reflect trends at individual institutions. But you can break the data down into institution type, and find that traditional humanities fields at private SLACs like my own (Davidson College) are pretty much at late-1980s levels.
Clearly we should be doing more to counter the perception that the humanities—and by extension, the liberal arts—are in crisis mode. My own experience in the classroom doesn’t support this notion, and neither does the data.
Digital Humanities at MLA 2014

This is a list of digitally-inflected sessions at the 2014 Modern Language Association Convention (Chicago, January 9-12). These sessions in some way address digital tools, objects, and practices in language, literary, textual, cultural, and media studies. The list also includes sessions about digital pedagogy and scholarly communication. The list stands at 78 entries, making up less than 10% of the total 810 convention slots. Please leave a comment if this list is missing any relevant sessions. Continue reading “Digital Humanities at MLA 2014”
The Poetics of Non-Consumptive Reading
")
“Non-consumptive research” is the term digital humanities scholars use to describe the large-scale analysis of a texts—say topic modeling millions of books or data-mining tens of thousands of court cases. In non-consumptive research, a text is not read by a scholar so much as it is processed by a machine. The phrase frequently appears in the context of the long-running legal debate between various book digitization efforts (e.g. Google Books and HathiTrust) and publishers and copyright holders (e.g. the Authors Guild). For example, in one of the preliminary Google Books settlements, non-consumptive research is defined as “computational analysis” of one or more books “but not research in which a researcher reads or displays substantial portions of a Book to understand the intellectual content presented within.” Non-consumptive reading is not reading in any traditional way, and it certainly isn’t close reading. Examples of non-consumptive research that appear in the legal proceedings (the implications of which are explored by John Unsworth) include image analysis, text extraction, concordance development, citation extraction, linguistic analysis, automated translation, and indexing. Continue reading “The Poetics of Non-Consumptive Reading”
no life no life no life no life: the 100,000,000,000,000 stanzas of House of Leaves of Grass

Mark Z. Danielewski’s House of Leaves is a massive novel about, among other things, a house that is bigger on the inside than the outside. Walt Whitman’s Leaves of Grass is a collection of poems about, among other things, the expansiveness of America itself.
What happens when these two works are remixed with each other? It’s not such an odd question. Though separated by nearly a century, they share many of the same concerns. Multitudes. Contradictions. Obsession. Physical impossibilities. Even an awareness of their own lives as textual objects.
To explore these connections between House of Leaves and Leaves of Grass I have created House of Leaves of Grass, a poem (like Leaves of Grass) that is for all practical purposes boundless (like the house on Ash Tree Lane in House of Leaves). Or rather, it is bounded on an order of magnitude that makes it untraversable in its entirety. The number of stanzas (from stanza, the Italian word for “room”) approximates the number of cells in the human body, around 100 trillion. And yet the container for this text is a mere 24K. Continue reading “no life no life no life no life: the 100,000,000,000,000 stanzas of House of Leaves of Grass”
The Century of the Fugitive and the Secret of the Detainee

The 21st century will be the century of the fugitive. Not because fugitives are proliferating, but because they are disappearing. And not disappearing in the way that fugitives like to disappear, but disappearing because they simply won’t exist. Technology won’t allow it.
A manhunt summons forth the great machinery of the state: scores of armed agents, ballistic tests and DNA samples, barking dogs, helicopters, infrared flybys. There is no evading it. It’s nearly impossible now to become a fugitive. And the more difficult fugitive life becomes, the more legendary fugitive figures become. As Peter Stallybrass and Allon White put it in their classic study of the grotesque and carnivalesque, “…what is socially peripheral is so frequently symbolically central.” The more marginalized and rare fugitives become, the greater the role they will play in our symbolic repertoire. In film, literature, music, art, videogames—in all these arenas, the fugitive will play a central role. Fugitives will come to occupy the same place in our collective consciousness as cowboys or pirates. And just as the Western film genre dominated the mid-20th century—while agribusiness was at the same time industrializing the west, making the cowboy superfluous—the 21st century will be dominated by the symbolic figure of the fugitive. Continue reading “The Century of the Fugitive and the Secret of the Detainee”