I’m spending July in Cádiz, Spain, with my family and a bunch of students from Davidson College. The other weekend we visited Granada, home of the Alhambra. Built by the last Arabic dynasty on the Iberian peninsula in the 13th century, the Alhambra is a stunning palace overlooking the city below. The city of Granada itself—like several other cities in Spain—is a palimpsest of Islamic, Jewish, and Christian art, culture, and architecture.
Take the streets of Granada. In the Albayzín neighborhood the cobblestone streets are winding, narrow alleys, branching off from each other at odd angles. Even though I’ve wandered Granada several times over the past decade, it’s easy to get lost in these serpentine streets. The photograph above (Flickr source) of the Albayzín, shot from the Alhambra, can barely reveal the maze that these medieval Muslim streets form. The Albayzín is a marked contrast to the layout of historically Christian cities in Spain. Influenced by Roman design, a typical Spanish city features a central square—the Plaza Mayor—from which streets extend out at right angles toward the cardinal points of the compass. Whereas the Muslim streets are winding and organic, the Christian streets are neat and angular. It’s the difference between a labyrinth and a grid.
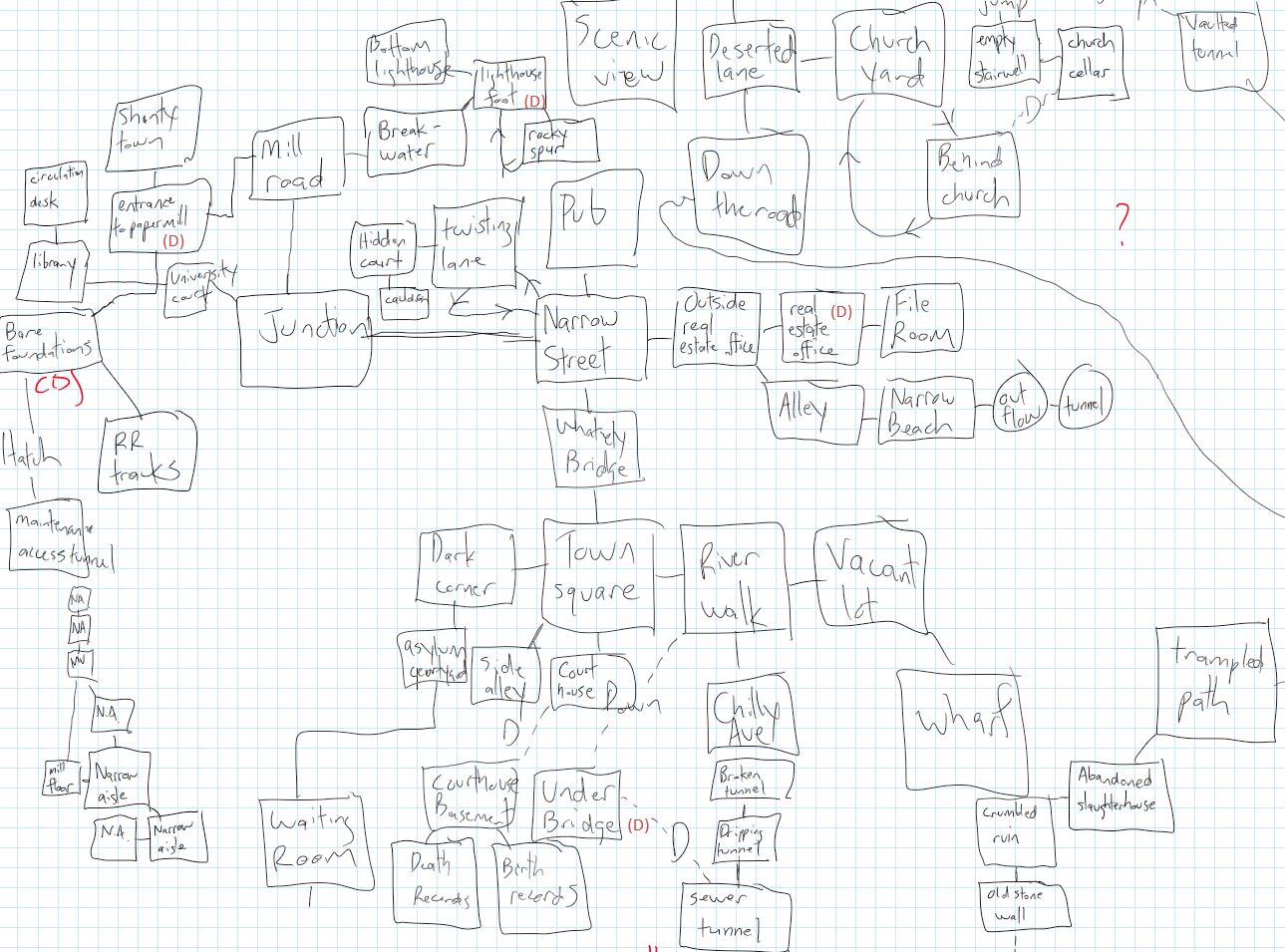
It just so happened that on our long bus ride to Granada I finished playing Anchorhead, Michael Gentry’s monumental work of interactive fiction (IF) from 1998. Even if you’ve never played IF, you likely recognize it when you see it, thanks to the ongoing hybridization of geek culture with pop culture. Entirely text-based, these story-games present puzzles and narrative situations that you traverse through typed commands, like GO NORTH, GET LAMP, OPEN JEWELED BOX, etc. As for Anchorhead, it’s a Lovecraftian horror with cosmic entities, incestual families, and the requisite insane asylum. Anchorhead also includes a mainstay of early interactive fiction: a maze.
Two of them in fact.
It’s difficult to overstate the role of mazes in interactive fiction. Will Crowther and Don Woods’ Adventure (or Colossal Cave) was the first work of IF in the mid-seventies. It also had the first maze, a “maze of twisty little passages, all alike.” Later on Zork would have a maze, and so would many other games, including Anchorhead. Mazes are so emblematic of interactive fiction that the first scholarly book on the subject references Adventure‘s maze in its title: Nick Montfort’s Twisty Little Passages: An Approach to Interactive Fiction (MIT Press, 2003). Mazes are also singled out in the manual for Inform 7, a high level programming language used to create many contemporary works of interactive fiction. As the official Inform 7 “recipe book” puts it, “Many old-school IF puzzles involve journeys through the map which are confused, randomised or otherwise frustrated.” Mazes are now considered passé in contemporary IF, but only because they were used for years to convey a sense of disorientation and anxiety.
And so, there I was in Granada having just played one of the most acclaimed works of interactive fiction ever. It occurred to me then, among the twisty little passages of Granada, that a relationship exists between the labyrinthine alleys of the Albayzín and the way interactive fiction has used mazes.
See, the usual way of navigating interactive fiction is to use cardinal directions. GO WEST. SOUTHEAST. OPEN THE NORTH DOOR. The eight points of the compass rose is an IF convention that, like mazes, goes all the way back to Colossal Cave. The Inform 7 manual briefly acknowledges this convention in its section on rooms:
In real life, people are seldom conscious of their compass bearing when walking around buildings, but it makes a concise and unconfusing way for the player to say where to go next, so is generally accepted as a convention of the genre.
Let’s dig into this convention a bit. Occasionally, it’s been challenged (Aaron Reed’s BlueLacuna comes to mind), but for the most part, navigating interactive fiction with cardinal directions is simply what you expect to do. It’s essentially a grid system that helps players mentally map the game’s narrative spaces. Witness my own map of Anchorhead, literally drawn on graph paper as I played the game (okay, I drew it on OneNote on an iPad, but you get the idea):
My partial map of Anchorhead, drawn by hand
And when IF wants to confuse, frustrate, or disorient players, along comes the maze. Labyrinths, the kind evoked by the streets of the Albayzín, defy the grid system of Western logic. Mazes in interactive fiction are defined by the very breakdown of the compass. Direction don’t work anymore. The maze evokes otherness by defying rationality.
When the grid/maze dichotomy of interactive fiction is mapped onto actual history—say the city of Granada—something interesting happens. You start to see the the narrative trope of the maze as an essentially Orientalist move. I’m using “Orientalist” here in the way Edward Said uses it, a name for discourse about the Middle East that mysticizes yet disempowers the culture and its people. As Said describes it, Orientalism is part of a larger project of dominating that culture and its people. Orientalist tropes of the Middle East include ahistorical images that present an exotic, irrational counterpart to the supposed logic of European modernity. In an article in the European Journal of Cultural Studies about the representation of Arabs in videogames, Vít Ŝisler provides a quick list of such tropes. They include “motifs such as headscarves, turbans, scimitars, tiles and camels, character concepts such as caliphs, Bedouins, djinns, belly dancers and Oriental topoi such as deserts, minarets, bazaars and harems.” In nearly every case, for white American and European audiences these tropes provide a shorthand for an alien other.
My argument is this:
Interactive fiction relies on a Christian-influenced, Western European-centric sense of space. Grid-like, organized, navigable. Mappable. In a word, knowable.
Occasionally, to evoke the irrational, the unmappable, the unknowable, interactive fiction employs mazes. The connection of these textual mazes to the labyrinthine Middle Eastern bazaar that appears in, say Raiders of the Lost Ark, is unacknowledged and usually unintentional.
We cannot truly understand the role that mazes play vis-à-vis the usual Cartesian grid in interactive fiction unless we also understand the interplay between these dissimilar ways of organizing spaces in real life, which are bound up in social, cultural, and historical conflict. In particular, the West has valorized the rigid grid while looking with disdain upon organic irregularity.
Notwithstanding exceptions like Lisa Nakamura and Zeynep Tufekci, scholars of digital media in the U.S. and Europe have done a poor job looking beyond their own doorsteps for understanding digital culture. Case in point: the “Maze” chapter of 10 PRINT CHR$(205.5+RND(1)); : GOTO 10 (MIT Press, 2012), where my co-authors and I address the significance of mazes, both in and outside of computing, with nary a mention of non-Western or non-Christian labyrinths. In hindsight, I see the Western-centric perspective of this chapter (and others) as a real flaw of the book.
I don’t know why I didn’t know at the time about Laura Marks’ Enfoldment and Infinity: An Islamic Genealogy of New Media Art (MIT Press, 2010). Marks doesn’t talk about mazes per se, but you can imagine the labyrinths of Albayzín or the endless maze design generated by the 10 PRINT program as living enactments of what Marks calls “enfoldment.” Marks sees enfoldment as a dominant feature of Islamic art and describes it as the way image, information, and the infinite “enfold each other and unfold from one another.” Essentially, image gives way to information which in turn is an index (an impossible one though) to infinity itself. Marks argues that this dynamic of enfoldment is alive and well in algorithmic digital art.
With Marks, Granada, and interactive fiction on my mind, I have a series of questions. What happens when we shift our understanding of mazes from non-Cartesian spaces meant to confound players to transcendental expressions of infinity? What happens when we break the convention in interactive fiction by which grids are privileged over mazes? What happens when we recognize that even with something as non-essential to political power as a text-based game, the underlying procedural system reinscribes a model that values one valid way of seeing the world over another, equally valid way of seeing the world?
Header Image: Anh Dinh, “Albayzin from Alhambra” on Flickr (August 10, 2013). Creative Commons BY-NC license.
Like the pair of mice in Leo Lionni’s classic children’s book, I had a busy year in 2012. It was a great year, but an exhausting one.
The year began last January with a surprise: I was mentioned by Stanley Fish in an anti-digital humanities screed in the New York Times. That’s something I can check off my bucket list. (By the way, my response to Fish fit inside a tweet.) Ironically, had Fish read my chapter in Debates in the Digital Humanities, which was published the very same week, he might have seen some strange correspondences between his stance toward the digital humanities and my own. This chapter, “Unseen and Unremarked On: Don DeLillo and the Failure of the Digital Humanities,” has recently become open-access, along with the rest of the book. Hats off to Matt Gold, the Debates editor, as well as his crew at the Graduate Center at CUNY and the University of Minnesota Press for making the book possible in the first place, and open and online in the second place.
In January I also performed my first public reading of one of my creative works— Takei, George—during the off-site electronic literature reading at the 2012 MLA Convention in Seattle. There’s even grainy documentary footage of this reading, thanks to the efforts of the organizers Dene Grigar, Lori Emerson, and Kathi Inmans Berens. I also gave a well-received talk at the MLA about another work of electronic literature, Erik Loyer’s beautiful Strange Rain. And finally in January, I spent odd moments at the convention huddled in a coffee shop (this was Seattle, after all) working with my co-authors on the final revisions of a book manuscript. More about that book later in this post.
All of this happened in the first weeks of January. And the rest of the year was equally as busy. In addition to my regular commuting life, I traveled a great deal to conferences and other gatherings. As I mentioned, I presented at the MLA, but I also talked at the Society for Cinema and Media Studies convention (Boston in March), Computers and Writing (Raleigh in May), the Electronic Literature Organization (Morgantown in June), and the Society for Literature, Science, and the Arts (Milwaukee in September). In May I was a co-organizer of THATCamp Piedmont, held on the campus of Davidson College. During the summer I was a guest at the annual Microsoft Research Faculty Summit (Redmond in July). In the fall I was an invited panelist for my own institution’s Forum on the Future of Higher Education (in October) and an invited speaker for the University of Kansas’s Digital Humanities seminar (in November).
If the year began the publication of a modest—and frankly, immensely fun to write—chapter in an edited book, then I have to point out that it ended with the publication of a much larger (and challenging and unwieldy) project, a co-authored book from MIT Press: 10 PRINT CHR$(205.5+RND(1));: GOTO 10 (or 10 PRINT, as we call it). I’ve already written about the book, and I expect more posts will follow. I’ll simply say now that my co-authors and I are grateful for and astonished by its bestselling (as far as academic books go) status: within days of its release, the book was ranked #1,375 on Amazon, out of 8 million books. This figure is all the most astounding when you consider that we released a free PDF version of the book on the same day as its publication. More evidence that giving away things is the best way to also sell things.
I was busy with other scholarly projects throughout 2012 as well. I finished revisions of a critical code studies essay that will appear in the next issue of Digital Humanities Quarterly, and I wrapped up a chapter for an edited collection coming out from Routledge on mobile media narratives. I also continued to publish in unconventional but peer-reviewed venues. Most notably, Enculturation and the Journal of Digital Humanities, which has published two pieces of mine. On the flip side of peer-review, I read and wrote reader’s reports for several journals and publishers, including University of Minnesota Press, MIT Press, Routledge, and Digital Humanities Quarterly. (You see how the system works: once you publish with a press it’s not long until they ask you to review someone else’s work for them. Review it forward, I say.)
In addition to scholarly work, I’ve invested more time than ever this year in creative work. On the surface my creative work is a marginal activity—and often marginalized when it comes time to count in my annual faculty report. But I increasingly see my creativity and scholarship bound up in a virtuous circle. I’ve already mentioned my first fully-functional work of electronic literature, “Takei, George.” In June this piece appeared as a juried selection in Electrifying Literature: Affordances and Constraints, a media art exhibit held in conjunction with the 2012 Electronic Literature Organization conference. A tip to other scholars who aim to do more creative work: submit your work to juried exhibitions or other curated shows; if your work is selected, it’s the equivalent of peer-review and your creative work suddenly passes the threshold needed to appear on CVs and faculty activity reports. Another creative project of mine, Postcard for Artisanal Tweeting, appeared in Rough Cuts: Media and Design in Process, an online exhibit curated by Kari Kraus on The New Everyday, a Media Commons Project.
My own blog is another site where I blend creativity and scholarship. My recent post on Intrusive Scaffolding is as much a creative nonfiction piece as it is scholarship (more so, in fact). And my favorite post of 2012 began as an inside joke about scholarly blogs. The background is this: during a department meeting discussion about how blogging should be recognized in our annual infrequent merit salary raises, a senior colleague expressed concern that one professor’s cupcake blog would count as much as another professor’s research-oriented blog. In response to this discussion, I wrote a blog post about cupcakes that blended critical theory and creativity. And cursing. The post struck a nerve, and it was my most widely read and retweeted blog post ever. About cupcakes.
Late in 2012 my creative work took me into new territory: Twitterbots, those autonomous “agents” on Twitter that are occasionally useful and often annoying. My bot Citizen Canned is in the process of tweeting every unique word from the script of Citizen Kane, by order of frequency (as opposed to, say, by order of significance, which would have a certain two syllable word appear first). With roughly 4,400 unique words to tweet, at a rate of once per hour, I estimate that Citizen Kane will tweet the least frequently used word in the movie sometime five months from now.Another of the Twitterbots I built in 2012 is 10print_ebooks. This bot mashes up the complete text of my 10 PRINT book and generates occasionally nonsensical but often genius Markov chain tweets from it. The bot also incorporates text from other tweets that use the #10print hashtag, meaning it “learns” from the community. The Citizen Cane bot runs in PHP while the 10 PRINT bot is built in Processing.
Alongside this constant scholarly and creative work (not to mention teaching) ran a parallel timeline, mostly invisible. This was me, waiting for my tenure decision to be handed down. In the summer of 2011 I submitted my materials and by December 2011, I learned that my department had voted unanimously in my favor. Next, in January 2012 the college RPT (Rank-Promotion-Tenure) committee voted 10-2 in my favor. It’s a bit crazy that the committee report echoes what I’ve heard about my work since grade school:
Mark Sample presents an unusual case. His work is at the edge of his discipline’s interaction with digital media technology. It blurs the lines between scholarship, teaching, and service in challenging ways. It also marks the point where traditional scholarly peer review meets the public interface of the internet. This makes for some difficulty in assessing his case.
In February my dean voted in favor of my case too. Next came the provost’s support at the end of March. In a surprise move, the provost recommended me for tenure on two counts: genuine excellence in teaching and genuine excellence in research. Professors usually earn tenure on the strength of their research alone. It’s uncommon to earn tenure at Mason on excellence in teaching, and an anomaly to earn tenure for both. By this point, approval from the president and the Board of Visitors (our equivalent of a Board of Trustees) might have seemed like rubber stamps, but I wasn’t celebrating tenure as a done deal. In fact, when I finally received the official notice—and contract—in June, I still didn’t feel like celebrating. And by the time my tenure and promotion went into effect in August 2012, I was too busy gearing up for the semester (and indexing 10 PRINT) to think much about it.
In other words, I reached the end of 2012 without celebrating some of its best moments. On the other hand, I feel that most of its “best moments” were actually single instances in ongoing processes, and those processes are never truly over. 10 PRINT may be out, but I’m already looking forward to future collaborations with some of my co-authors. I wrote a great deal in 2012, but much of that occurred serially in places like ProfHacker, Play the Past, and Media Commons, where I will continue to write in 2013 and beyond.
What else with 2013 bring? I am working on two new creative projects and I have begun sketching out a new book project as well. Next fall I will begin a year-long study leave (Fall 2013/Spring 2014), and I aim to make significant progress on my book during that time. Who knows what else 2013 will bring. Maybe sleep?
Seeking to have a rich discussion period—which we did indeed have—we limited our talks to about 12 minutes each. My presentation was therefore more evocative than comprehensive, more open-ended than conclusive. There are primary sources I’m still searching for and technical details I’m still sorting out. I welcome feedback, criticism, and leads.
An Account of Randomness in Literary Computing
Mark Sample
MLA 2013, Boston
There’s a very simple question I want to ask this evening:
Where does randomness come from?
Randomness has a rich history in arts and literature, which I don’t need to go into today. Suffice it to say that long before Tristan Tzara suggested writing a poem by pulling words out of a hat, artists, composers, and writers have used so-called “chance operations” to create unpredictable, provocative, and occasionally nonsensical work. John Cage famously used chance operations in his experimental compositions, relying on lists of random numbers from Bell Labs to determine elements like pitch, amplitude, and duration (Holmes 107–108). Jackson Mac Low similarly used random numbers to generate his poetry, in particular relying on a book called A Million Random Digits with 100,000 Normal Deviates to supply him with the random numbers (Zweig 85).
Million Random Digits with 100,000 Normal Deviates
Published by the RAND Corporation in 1955 to supply Cold War scientists with random numbers to use in statistical modeling (Bennett 135), the book is still in print—and you should check out the parody reviews on Amazon.com. “With so many terrific random digits,” one reviewer jokes, “it’s a shame they didn’t sort them, to make it easier to find the one you’re looking for.”
This joke actually speaks to a key aspect of randomness: the need to reuse random numbers, so that, say you’re running a simulation of nuclear fission, you can repeat the simulation with the same random numbers—that is, the same probability—while testing some other variable. In fact, most of the early work on random number generation in the United States was funded by either the U.S. Atomic Commission or the U.S. Military (Montfort et al. 128). The RAND Corporation itself began as a research and development arm of the U.S. Air Force.
Now the thing with going down a list of random numbers in a book, or pulling words out of hat—a composition method, by the way, Thom Yorke used for Kid A after a frustrating bout of writer’s block—is that the process is visible. Randomness in these cases produces surprises, but the source itself of randomness is not a surprise. You can see how it’s done.
What I want to ask here today is, where does randomness come from when it’s invisible? What’s the digital equivalent of pulling words out of a hat? And what are the implications of chance operations performed by a machine?
To begin to answer these questions I am going to look at two early works of electronic literature that rely on chance operations. And when I say early works of electronic literature, I mean early, from fifty and sixty years ago. One of these works has been well studied and the other has been all but forgotten.
My first case study is the Strachey Love Letter Generator. Programmed by Christopher Strachey, a close friend of Alan Turing, the Love Letter Generator is likely—as Noah Wardrip-Fruin argues—the first work of electronic literature, which is to say a digital work that somehow makes us more aware of language and meaning-making. Strachey’s program “wrote” a series of purplish prose love letters on the Ferranti Mark I Computer—the first commercially available computer—at Manchester University in 1952 (Wardrip-Fruin “Digital Media” 302):
DARLING SWEETHEART
YOU ARE MY AVID FELLOW FEELING. MY AFFECTION CURIOUSLY CLINGS TO YOUR PASSIONATE WISH. MY LIKING YEARNS FOR YOUR HEART. YOU ARE MY WISTFUL SYMPATHY: MY TENDER LIKING.
YOURS BEAUTIFULLY
M. U. C.
Affectionately known as M.U.C., the Manchester University Computer could produce these love letters at a pace of one per minute, for hours on end, without producing a duplicate.
The “trick,” as Strachey put it in a 1954 essay about the program (29-30), is its two template sentences (Myadjectivenounadverbverb your adjectivenoun and You are my adjectivenoun) in which the nouns, adjectives, and adverbs are randomly selected from a list of words Strachey had culled from a Roget’s thesaurus. Adverbs and adjectives randomly drop out of the sentence as well, and the computer randomly alternates the two sentences.
The Love Letter Generator has attracted—for a work of electronic literature—a great deal of scholarly attention. Using Strachey’s original notes and source code (see figure to the left), which are archived at the Bodleian Library at the University of Oxford, David Link has built an emulator that runs Strachey’s program, and Noah Wardrip-Fruin has written a masterful study of both the generator and its historical context.
As Wardrip-Fruin calculates, given that there are 31 possible adjectives after the first sentence’s opening possessive pronoun “My” and then 20 possible nouns that could that could occupy the following slot, the first three words of this sentence alone have 899 possibilities. And the entire sentence has over 424 million combinations (424,305,525 to be precise) (“Digital Media” 311).
A partial list of word combinations for a single sentence from the Strachey Love Letter Generator
On the whole, Strachey was publicly dismissive of his foray into the literary use of computers. In his 1954 essay, which appeared in the prestigious trans-Atlantic arts and culture journal Encounter (a journal, it would be revealed in the late 1960s, that was primarily funded by the CIA—see Berry, 1993), Strachey used the example of the love letters to illustrate his point that simple rules can generate diverse and unexpected results (Strachey 29-30). And indeed, the Love Letter Generator qualifies as an early example of what Wardrip-Fruin calls, referring to a different work entirely, the Tale-Spin effect: a surface illusion of simplicity which hides a much more complicated—and often more interesting—series of internal processes (Expressive Processing 122).
Wardrip-Fruin coined this term—the Tale-Spin effect—from Tale-Spin, an early story generation system designed by James Mehann at Yale University in 1976. Tale-Spin tended to produce flat, plodding narratives, though there was the occasional existential story:
Henry Ant was thirsty. He walked over to the river bank where his good friend Bill Bird was sitting. Henry slipped and fell in the river. He was unable to call for help. He drowned.
But even in these suggestive cases, the narratives give no sense of the process-intensive—to borrow from Chris Crawford—calculations and assumptions occurring behind the interface of Tale-Spin.
In a similar fashion, no single love letter reveals the combinatory procedures at work by the Mark I computer.
JEWEL MOPPET
MY AFFECTION LUSTS FOR YOUR TENDERNESS. YOU ARE MY PASSIONATE DEVOTION: MY WISTFUL TENDERNESS. MY LIKING WOOS YOUR DEVOTION. MY APPETITE ARDENTLY TREASURES YOUR FERVENT HUNGER.
YOURS WINNINGLY
M. U. C.
This Tale-Spin effect—the underlying processes obscured by the seemingly simplistic, even comical surface text—are what draw Wardrip-Fruin to the work. But I want to go deeper than the algorithmic process that can produce hundreds of millions of possible love letters. I want to know, what is the source of randomness in the algorithm? We know Strachey’s program employs randomness, but where does that randomness come from? This is something the program—the source code itself—cannot tell us, because randomness operates at a different level, not at the level of code or software, but in the machine itself, at the level of hardware.
In the case of Strachey’s Love Letter Generator, we must consider the computer it was designed for, the Mark I. One of the remarkable features of this computer was that it had a hardware-based random number generator. The random number generator pulled a string of random numbers from what Turing called “resistance noise”—that is, electrical signals produced by the physical functioning of the machine itself—and put the twenty least significant digits of this number into the Mark I’s accumulator—its primary mathematical engine (Turing). Alan Turing himself specifically requested this feature, having theorized with his earlier Turing Machine that a purely logical machine could not produce randomness (Shiner). And Turing knew—like his Cold War counterparts in the United States—that random numbers were crucial for any kind of statistical modeling of nuclear fission.
I have more to say about randomness in the Strachey Love Letter Generator, but before I do, I want to move to my second case study. This is an early, largely unheralded work called SAGA. SAGA was a script-writing program on the TX-0 computer. The TX-0 was the first computer to replace vacuum tubes with transistors and also the first to use interactive graphics—it even had a light pen.
The TX-0 was built at Lincoln Laboratory in 1956—a classified MIT facility in Bedford, Massachusetts chartered with the mission of designing the nation’s first air defense detection system. After TX-0 proved that transistors could out-perform and outlast vacuum tubes, the computer was transferred to MIT’s Research Laboratory of Electronics in 1958 (McKenzie), where it became a kind of playground for the first generation of hackers (Levy 29-30).
In 1960, CBS broadcast an hour-long special about computers called “The Thinking Machine.” For the show MIT engineers Douglas Ross and Harrison Morse wrote a 13,000 line program in six weeks that generated a climactic shoot-out scene from a Western.
Several computer-generated variations of the script were performed on the CBS program. As Ross told the story years later, “The CBS director said, ‘Gee, Westerns are so cut and dried couldn’t you write a program for one?’ And I was talked into it.”
The TX-0’s large—for the time period—magnetic core memory was used “to keep track of everything down to the actors’ hands.” As Ross explained it, “The logic choreographed the movement of each object, hands, guns, glasses, doors, etc.” (“Highlights from the Computer Museum Report”).
And here, is the actual output from the TX-0, printed on the lab’s Flexowriter printer, where you can get a sense of the way SAGA generated the play:
In the CBS broadcast, Ross explained the narrative sequence as a series of forking paths.
Each “run” of SAGA was defined by sixteen initial state variables, with each state having several weighted branches (Ross 2). For example, one of the initial settings is who sees whom first. Does the sheriff see the robber first or is it the other way around? This variable will influence who shoots first as well.
There’s also a variable the programmers called the “inebriation factor,” which increases a bit with every shot of whiskey, and doubles for every swig straight from the bottle. The more the robber drinks, the less logical he will be. In short, every possibility has its own likely consequence, measured in terms of probability.
The MIT engineers had a mathematical formula for this probability (Ross 2):
But more revealing to us is the procedure itself of writing one of these Western playlets.
First, a random number was set; this number determined the probability of the various weighted branches. The programmers did this simply by typing a number following the RUN command when they launched SAGA; you can see this in the second slide above, where the random number is 51455. Next a timing number established how long the robber is alone before the sheriff arrives (the longer the robber is alone, the more likely he’ll drink). Finally each state variable is read, and the outcome—or branch—of each step is determined.
What I want to call your attention to is how the random number is not generated by the machine. It is entered in “by hand” when one “runs” the program. In fact, launching SAGA with the same random number and the same switch settings will reproduce a play exactly (Ross 2).
In a foundational work in 1996 called The Virtual Muse Charles Hartman observed that randomness “has always been the main contribution that computers have made to the writing of poetry”—and one might be tempted to add, to electronic literature in general (Hartman 30). Yet the two case studies I have presented today complicate this notion. The Strachey Love Letter Generator would appear to exemplify the use of randomness in electronic literature. But—and I didn’t say this earlier—the random numbers generated by the Mark I’s method tended not to be reliably random enough; remember, random numbers often need to be reused, so that the programs that run them can be repeated. This is called pseudo-randomness. This is why books like the RAND Corporation’s A Million Random Digits is so valuable.
But the Mark I’s random numbers were so unreliable that they made debugging programs difficult, because errors never occurred the same way twice. The random number instruction eventually fell out of use on the machine (Campbell-Kelly 136). Skip ahead 8 years to the TX-0 and we find a computer that doesn’t even have a random number generator. The random numbers must be entered manually.
The examples of the Love Letters and SAGA suggest at least two things about the source of randomness in literary computing. One, there is a social-historical source; wherever you look at randomness in early computing, the Cold War is there. The impact of the Cold War upon computing and videogames has been well-documented (see, for example Edwards, 1996 and Crogan, 2011), but few have studied how deeply embedded the Cold War is in the software algorithms and hardware processes themselves of modern computing.
Second, randomness does not have a progressive timeline. The story of randomness in computing—and especially in literary computing—is neither straightforward nor self-evident. Its history is uneven, contested, and mostly invisible. So that even when we understand the concept of randomness in electronic literature—and new media in general—we often misapprehend its source.
WORKS CITED
Bennett, Deborah. Randomness. Cambridge, MA: Harvard University Press, 1998. Print.
Turing, A.M. “Programmers’ Handbook for the Manchester Electronic Computer Mark II.” Oct. 1952. Web. 23 Dec. 2012.
Wardrip-Fruin, Noah. “Digital Media Archaeology: Interpreting Computational Processes.” Media Archaeology: Approaches, Applications, and Implications. Ed by. Erkki Huhtamo & Jussi Parikka. Berkeley, California: University of California Press, 2011. Print.
—. Expressive Processing: Digital Fictions, Computer Games, and Software Sudies. MIT Press, 2009. Print.
Zweig, Ellen. “Jackson Mac Low: The Limits of Formalism.” Poetics Today 3.3 (1982): 79–86. Web. 1 Jan. 2013.
A Million Random Digits with 100,000 Normal Deviates. Courtesy of Casey Reas and10 PRINT CHR$(205.5+RND(1));: GOTO 10. Cambridge, Mass.: MIT Press, 2013. 129.
I’m delighted to announce the publication of10 PRINT CHR$(205.5+RND(1)); : GOTO 10 (MIT Press, 2013). My co-authors are Nick Montfort (who conceived the project), Patsy Baudoin, John Bell, Ian Bogost, Jeremy Douglass, Mark Marino, Michael Mateas, Casey Reas, and Noah Vawter. Published in MIT Press’s Software Studies series, 10 PRINTis about a single line of code that generates a continuously scrolling random maze on the Commodore 64. 10 PRINT is aimed at people who want to better understand the cultural resonance of code. But it’s also about aesthetics, hardware, typography, randomness, and the birth of home computing. 10 PRINT has already attracted attention from Bruce Sterling (who jokes that the title “really rolls off the tongue”), Slate, and Boing Boing. And we want humanists (digital and otherwise) to pay attention to the book as well (after all, five of the co-authors hold Ph.D.’s in literature, not computer science).
Aside from its nearly unpronounceable title, 10 PRINT is an unconventional academic book in a number of ways:
10 PRINT was written by ten authors in one voice. That is, it’s not a collection with each chapter written by a different individual. Every page of every chapter was collaboratively produced, a mind-boggling fact to humanists mired in the model of the single-authored manuscript. A few months before I knew I was going to work on 10 PRINT, I speculated that the future of scholarly publishing was going to be loud, crowded, and out of control. My experience with 10 PRINT bore out that theory—though the end product does not reflect the messiness of the writing process itself, which I’ll address in an upcoming post.
10 PRINT is nominally about a single line of code—the eponymous BASIC program for the Commodore 64 that goes 10 PRINT CHR$(205.5+RND(1)); : GOTO 10. But we use that one line of code as both a lens and a mirror to explore so much more. In his generous blurb for10 PRINT, Matt Kirschenbaum quotes William Blake’s line about seeing the world in a grain of sand. This short BASIC program is our grain of sand, and in it we see vast cultural, technological, social, and economic forces at work.
10 PRINT emerges at the same time that the digital humanities appear to be sweeping across colleges and universities, yet it stands in direct opposition to the primacy of “big data” and “distant reading”—two of the dominant features of the digital humanities. 10 PRINT is nothing if not a return to close reading, to small data. Instead of speaking in terms of terabytes and petabytes, we dwell in the realm of single bits. Instead of studying datasets of unimaginable size we circle iteratively around a single line of code, reading it again and again from different perspectives. Even single characters in that line of code—say, the semicolon—become subject to intense scrutiny and yield surprising finds.
10 PRINT practices making in order to theorize being. My co-author Ian Bogost calls it carpentry. I’ve called it deformative humanities. It’s the idea that we make new things in order to understand old things. In the case of 10 PRINT, my co-authors and I have written a number of ports of the original program that run on contemporaries of the C64, like the Atari VCS, the Apple IIe, and the TRS-80 Color Computer. One of the methodological premises of 10 PRINT is that porting—like the act of translation—reveals new facets of the original source. Porting—again, like translation—also makes visible the broader social context of the original.
In the upcoming days I’ll be posting more about 10 PRINT, discussing the writing process, the challenges of collaborative authorship, our methodological approaches, and of some of the rich history we uncovered by looking at a single line of code.
In the meantime, a gorgeous hardcover edition is available (beautifully designed by my co-author, Casey Reas). Or download a free PDF released under a Creative Commons BY-NC-SA license.
(This is the text of my five minute position statement on the role of computational literacy in computers and writing. I delivered this statement during a “town hall” meeting at the annual Computers and Writing Conference, hosted at North Carolina State University on May 19, 2012.)
I want to briefly run through five basic statements about computational literacy. These are literally 5 statements in BASIC, a programming language developed at Dartmouth in the 1960s. As some of you might know, BASIC is an acronym for Beginner’s All-Purpose Symbolic Instruction Code, and the language was designed in order to help all undergraduate students at Dartmouth—not just science and engineering students—use the college’s time-sharing computer system.
Each BASIC statement I present here is a fully functioning 1-line program. I want to use each as a kind of thesis—or a provocation of a thesis—about the role of computational literacy in computers and writing, and in the humanities more generally.
10 PRINT 2+3
I’m beginning with this statement because it’s a highly legible program that nonetheless highlights the mathematical, procedural nature of code. But this program is also a piece of history: it’s the first line of code in the user manual of the first commercially available version of BASIC, developed for the first commercially available home computer, the Altair 8800. The year was 1975 and this BASIC was developed by a young Bill Gates and Paul Allen. And of course, their BASIC would go on to be the foundation of Microsoft. It’s worth noting that although Microsoft BASIC was the official BASIC of the Altair 8800 (and many home computers to follow), an alternative version, called Tiny BASIC, was developed by a group of programmers in San Francisco. The 1976 release of Tiny BASIC included a “copyleft” software license, a kind of predecessor to contemporary open source software licenses. Copyleft emphasized sharing, an idea at the heart of the original Dartmouth BASIC.
10 PRINT “HELLO WORLD”
If BASIC itself was a program that invited collaboration, then this—customarily one of the first programs a beginner learns to write—highlights the way software looks outward. Hello, world. Computer code is writing in public, a social text. Or, what Jerry McGann calls a “social private text.” As McGann explains, “Texts are produced and reproduced under specific social and institutional conditions, and hence…every text, including those that may appear to be purely private, is a social text.”[1. McGann, Jerome. The Textual Condition. Princeton, NJ: Princeton University Press, 1991, p. 21.]
10 PRINT “GO TO STATEMENT CONSIDERED HARMFUL”: GOTO 10
My next program is a bit of an insider’s joke. It’s a reference to a famous 1968 diatribe by Edsger Dijkstra called “Go To Statement Considered Harmful.” Dijkstra argues against using the goto command, which leads to what critics call spaghetti code. I’m not interested in that specific debate, so much as I like how this famous injunction implies an evaluative audience, a set of norms, and even an aesthetic priority. Programming is a set of practices, with its own history and tensions. Any serious consideration of code—any serious consideration of computers—in the humanities must reckon with these social elements of code.
10 REM PRINT “GOODBYE CRUEL WORLD”
The late German media theorist Frederich Kittler has argued that, as Alexander Galloway put it, “code is the only language that does what it says.”[2. Galloway, Alexander R. Gaming: Essays on Algorithmic Culture. Minneapolis: University of Minnesota Press, 2006, p. 6] Yes, code does what it says. But it also says things it does not do. Like this one-line program which begins with REM, short for remark, meaning this is a comment left by a programmer, which the computer will not execute. Comments in code exemplify what Mark Marino has called the “extra-functional significance” of code, meaning-making that goes beyond the purely utilitarian commands in the code.[3. Marino, Mark C. “Critical Code Studies.” Electronic Book Review (2006). <http://www.electronicbookreview.com/thread/electropoetics/codology>.]
Without a doubt, there is much even non-programmers can learn not by studying what code does, but by studying what it says, and what it evokes.
10 PRINT CHR$(205.5+RND(1));:GOTO 10
Finally, here’s a program that highlights exactly how illegible code can be. Very few people could look at this program for the Commodore 64 and figure out what it does. This example suggests there’s a limit to the usefulness of the concept of literacy when talking about code. And yet, when we run the program, it’s revealed to be quite simple, though endlessly changing, as it creates a random maze across the screen.
So I’ll end with a caution about relying on the word literacy. It’s a word I’m deeply troubled by, loaded with historical and social baggage and it’s often misused as a gatekeeping concept, an either/or state; one is either literate or illiterate.
In my own teaching and research I’ve replaced my use of literacy with the idea of competency. I’m influenced here by the way teachers of a foreign language want their students to use language when they study abroad. They don’t use terms like literacy or fluency, they talk about competency. Because the thing with competency is, it’s highly contextualized, situated, and fluid. Competency means knowing the things that are required in order to do the other things you need to do. It’s not the same for everyone, and it varies by place, time, and circumstance.
Translating this experience to computers and writing, competency means reckoning with computation at the level appropriate for what you want to get out of it—or put into it.
I’ve had a sneak preview of MIT Press’s Fall 2012 catalog, and I’m delighted that the boldest project I’ve ever worked on is in there. The title is 10 PRINT CHR$(205.5+RND(1)); : GOTO 10 and it just gets crazier from there.
Ten authors.
Working by wiki style collaboration.
Studying one line of code.
For a thirty-year-old computer.
I’ll say more about 10 Print in the coming weeks, but for now, I just want to admire my co-author Casey Reas’s brilliant cover.