My last development diary entry looked at the origins of Babyface, my submission to the 2020 Interactive Fiction competition (IFComp). This dev diary entry looks at one of the first things reviewers say about Babyface: that it’s mostly linear. Usually this comes as a simple description of the game’s format, rather than a criticism. Because I did expect people to criticize the game for having such a linear-driven narrative. Babyface lacks some of the hallmarks of interactive fiction. There are no puzzles you can solve. And there are no choices that change the outcome of the game. This lack of choices is absolutely deliberate. So now I want to talk about my approach to the question of agency and choice (or lack thereof) in Babyface.
Babyface is categorized as “choice-based” on the IFComp list of entries. But I only selected “choice-based” as the category because Babyface clearly doesn’t fit the other available category, parser-based. Both categories carry with them a set of associations:
Parser-based games generally revolve around puzzles and occasionally riddles.
Choice-based games generally involve, well, choices, and ideally choices that have some sort of meaningful impact on the game.
If there had been a “hypertext” category, that’s what I would have selected for Babyface. I like the hypertext designation because it retains some of the expectations of the choice-based formats (you’re clicking on links rather than typing commands into a parser) but it shifts the focus away from the actual choices. “Hypertext” opens the door for thinking about links as something other than choices. In Babyface you can probably see this most clearly in the late Thursday night / early Friday morning sequence, when you find yourself back at the Babyface House. You find the same link multiple times in a row, and each time you select it the link remains the same, while the text slowly expands:
You could think of this as a kind of stretchtext. But rather than expanding the narrative by filling in gaps (say, like the stretchtext in Pry), it conveys a paradoxical sense of standing still while nonetheless moving forward.
If I were to drag in narrative theory (yes, I’m going to drag in narrative theory), I think about how Marie-Laure Ryan places interactivity in digital games into two distinct categories. There’s interactivity that corresponds to the player’s perspective: are they embedded in the game as a participant in the story (internal interactivity), or are they looking down from an omniscient godlike perch (external interactivity). And there’s interactivity that corresponds to the kind of actions available to the player, what Ryan calls exploratory versus ontological interactivity. Does the player probe an existing world or set of choices (exploratory interactivity), or does the player have the power to change the game world itself, as in Minecraft (ontological interactivity). I picture these kinds of interactivity like this, along two axes:
A game like The Sims or Civ fits in the external-ontological quadrant. You might consider a first-person shooter to be internal-ontological, depending on how much you think killing NPCs changes the game world might. Babyface clearly fits within the internal-exploratory quadrant. You play as a character, about whom you can glean some details and personal history as the game progresses. That’s internal interactivity. And you can only move about in a world I have strictly delineated. That’s exploratory interactivity. There’s nothing you can do in the game world to change it.
The exploratory nature of the game is heightened by the occasional loop with in-game documents, like the old Polaroid photographs. When the narrator’s father hands her a set of four photos, you can click each multiple times, and each time reveals a different description. In this way I’m trying to convey a sense of discovery about the history of Babyface, one piece of evidence at a time. I programmed that sequence so that it always moves on to the next narrative beat before the narrator’s had a chance to see every description of the photographs. No matter what order you click the photos, there will always be one description you don’t get a chance to see. My hope is that that last piece of evidence becomes an Easter Egg that draws players with a completionist mindset to go through the game again.
So internal-exploratory interactivity. But there’s another kind of interaction with Babyface (ideally, though this won’t be true for all players) that the four quadrants of interactivity doesn’t capture. I call this epistemological interactivity. Epistemological, that’s a mouthful. What I mean by epistemological is the nature of knowledge and knowing in the game. I picture epistemology as a Z axis that juts forward and backward from my graph above, intersecting with the other two axes.
So there’s internal-ontological-epistemological interactivity. That’s solving puzzles in the game that would have an impact on the game world. Of which in Babyface there are none. Then there’s internal-exploratory-epistemological (IEE) interactions, which are mysteries in the game that you can try to figure out, but which won’t impact the game world itself. You could argue that learning how to work the interface is an internal-exploratory-epistemological puzzle. For example, figuring out that at certain points the narrative will only proceed after you click on the photographs several times each. Piecing together details of the narrator’s life is another IEE mystery, as is the story of her mother and Babyface.
But, while there are plenty of clues about the nature of the relationship between the narrator’s mother and Babyface, there’s nothing in the game to definitively explain it. At the heart of Babyface are several kernels of sheer irrationality. To reach any kind of narrative closure about the game, you have to reach beyond the game. That’s external-exploratory-epistemological interactivity. A little bit of research, a little bit of Googling, and some of the odd pieces of Babyface hopefully begin to—well, if not make sense, then at least cohere. One of my early taglines for the game hinted at this nondiegetic epistemological interactivity: “A Southern Gothic horror story, where the only puzzles are metaphysical.” What I meant was, the puzzles the game poses spill beyond the borders of the game.
Another way I conceived of Babyface early on was as a Southern Gothic creepypasta story. I stopped referring to the game as creepypasta, though, because that word (like parser-based or choice-based) carries associations I didn’t necessarily want attached to Babyface. Nevertheless, the game does share a family resemblance to creepypasta. As I see it, two key features of creepypasta (as a genre of fiction, not as a website or Internet phenomenon) are (1) irrationality disrupts the every day world; and (2) there’s a blurring between the inside and outside of the story, raising the specter that the story really happened. Both features operate within the realm of epistemology: What really happened? How do we know? Could it have really happened? Could it happen again?
Those epistemological questions are what I hope the close reader of Babyface walks away with, rattling in their heads. It’s an engagement with the story—interactivity—that happens outside the story itself. For the story I wanted to tell—which is ultimately a story about the year 2020 and the decades leading up to it—this kind of epistemological agency mattered more to me than player agency.
So, Babyface is a thing I made. It’s a creepypasta-style Southern Gothic horror story. I’ve entered the game into the 26th annual Interactive Fiction Competition (IFComp for short). You can play Babyface right now! I’ve followed IFComp for years—since at least 2007—but this is the first time I’ve made anything for the competition. Not that I haven’t wanted to, but finally everything lined up: my idea, the time to write it, the skills to do it, and finally the deliberate shift in my professional life from conventional scholarship to creative coding.
IFComp authors often share a “developer’s diary” that details their creative and coding process. I don’t really consider myself a developer. I’m more of a “I make weird things for the internet” person. But still, I thought I’d give this dev diary thing a try. If nothing else, than to debrief myself about the design process. I’ve blurred the text of any spoilers—just hover or tap on the blurred text to read it.
Babyface wasn’t supposed to be my game for IFComp. I was working on another game, a much larger game, a counterfactual history of eugenics in America. The game is basically asking what if CRISPR-like gene editing technology had been invented in the 1920s, the height of the eugenics movement. The game is heavily researched and includes meaningful choices (unlike Babyface, which is more or less on rails). But! But! But—I ended up talking about the game in conference talks and symposiums and showing it to enough people that it felt like it would be disqualified for IFComp, which has a strict rule that the competition must be the public debut of the game. So I released that game (or rather, the first “chapter” of it) back in May as You Gen #9. Play it, please!
Anyway, I was left without a game, which was fine. But then I had a horrific nightmare in May, and I couldn’t get one image out of my head. It literally haunted me. And then in July Stacey Mason on Twitter announced a fortnightly interactive fiction game jam. So I started playing around with my nightmare, trying to give it context and a narrative frame. Pretty quickly I realized the game was going to be too ambitious (LOL, it’s really quite a modest game, but it felt ambitious to me) to finish in two weeks for a game jam. So I continued working on the game all through August and September. On one hand three months to put together a polished game is not a lot of time. On the other hand, I had been working in Twine almost every day for the past year, and the story is modest (my best estimate is around 16,000 words, though it’s tough to measure word counts in a game with dynamic text). Plus there’s not a lot of state logic to keep track off. No complicated inventory systems, no clever NPCs. Just the narrator, a few interactions, and her memories.
I’ll talk more about specific design choices in a future post, but for now I wanted to say a few words about the setting. Like most Gothic fiction, the setting itself is a character in the game.
I was working with a concrete geography in Babyface. The old brick house is based on a real house in my small North Carolina college town. I could walk there right now in about 20 minutes, all on pleasant neighborhood streets. Less than five minutes by car. A recluse lived there, and the house, as in the game, is down the street from the local elementary school. The recluse died a few years ago, and it was some time before anybody even knew. Somebody eventually bought the property, tore down the old brick house, and put up a gaudy McMansion.
One detail I had wanted to include in the game but decided against, because it would have seemed too unbelievable: between the old house and the elementary school there’s a cemetery. I had considered incorporating the cemetery into the story as the narrator runs away from the house, but it just seemed too forced. One of those instances where real life out-narrativizes fiction, and in order to make the fiction more palatable, you have to dial back the realism.
The Southern backdrop is understated, though I dropped in enough clues that some readers might realize the centrality of the South in the game. More about those later…
In my previous post I listed all the digital creative/critical works I’ve released in the past 12 months. (Whew, it was a lot, in part because I had the privilege to be on sabbatical from teaching in the fall, my first sabbatical since 2006. I made the most of it.)
Now, I want to provide a long overdue introduction to each of my newest works, one post at a time. Let’s start with An End of Tarred Twine, a procedurally-generated hypertext version of Moby-Dick. I made An End of Tarred Twine for NaNoGenMo 2019 (National Novel Generation Month), in which the goal is to write code that writes a 50,000 word novel. Conceived by Darius Kazemi in 2013, NaNoGenMo runs every November, parallel to National Novel Writing Month. I’ve always wanted to participate in NaNoGenMo, but the timing was never good. It falls right during the crunch period of the fall semester. But, hey, I wasn’t teaching last fall, so I could hunker down and finally try something.
An End of Tarred Twine is what I came up with. The title is a line from Moby-Dick, where Captain Bildad, one of the Quaker owners of the Pequod is fastidiously preparing the ship for its departure from Nantucket. As sailmakers mend a top-sail, Bildad gathers up small swatches of sailcloth and bits of tarred twine on the deck that “otherwise might have been wasted.” That Captain Bildad saves even the smallest scrap of waste speaks to his austere—one might say cheap—nature. The line is also one of the few references to twine in the novel. This was important to me because An End of Tarred Twine is made in Twine, an open source platform for writing interactive, nonlinear hypertext narratives.
An End of Tarred Twine is like the white whale itself—at once monstrous and elusive. And that’s because all the links and paths are randomly generated. You start off on the well-known first paragraph of Moby-Dick—Call me Ishmael & etc.—but random links in that passage lead to random passages, which lead to other random passages. Very quickly, you’re lost, reading Moby-Dick one passage at a time, out of order, with no map to guide you. Or as Ishmael says about the birthplace of Queequeg, the location “is not down in any map; true places never are.”
A Monstrous Hypertext
Here, this GIF shows you what I mean. It starts with the start of Moby Dick but quickly jumps into uncharted waters.
Clicking through the opening sequence of An End of Tarred Twine
This traversal starts off in chapter 1, jumps to chapter 24, then on to chapter 105, and so on. One paragraph at a time, in random order, with no logic behind the links that move from passage to passage. As a reading experience, it’s more conceptual than practical, akin to the Modernist-inflected hypertext novels of the 1980s. As a technical experiment, I personally think there’s some interesting stuff going on.
Look at these stats. An End of Tarred Twine has:
250,051 words (the same as Moby Dick, minus the Etymology and Extracts that precede the body of the novel)
2,463 passages (or what old school hypertext theorists would call lexias)
6,476 links between the passages
2.63 average links on any single passage
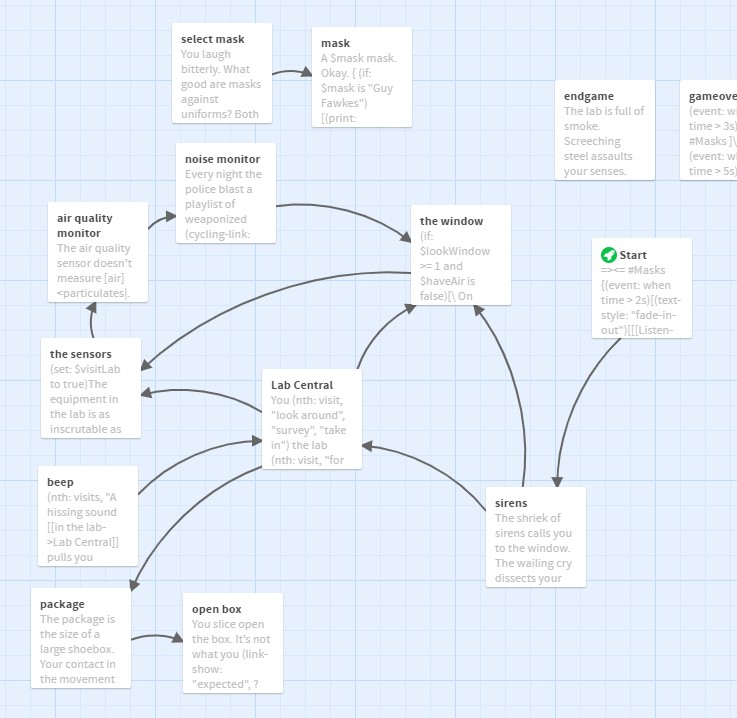
Another visual might help you appreciate the complexity of the work. One of the cool features of the official Twine app (i.e. where you write and code your interactive narrative) is that Twine maps each passage on a blueprint-like grid. For the typical Twine project, this narrative map offers a quick overview of the narrative structure of your story. For example, here’s what Masks, one of my other recent projects, looks like on the backend in Twine:
A map of Masks in Twine
Each black line and arrow represents a link from one passage to the next. Now look at what An End of Tarred Twine looks like on the backend in Twine:
An End of Tarred Twine in Twine
The first passage (labeled 0) is the title screen, with the word “Loomings” linking to the second passage (1). You can see that passage then has outbound links as well as some inbound links. Here’s another view, deeper into the hypertext:
Lost in the map of An End of Tarred Twine in Twine
There are so many links between passages by this point that the link lines become a dense forest of scribbles. You can almost image those lines as a detail taken from Rockwell Kent’s stunning illustration of Moby Dick breaching the ocean in his 1930 edition of Moby-Dick.
Workflow
Now, how did I create this unnavigable monstrosity? The point of NaNoGenMo is that you write the code that writes the novel. That’s really the only criteria. The novel itself doesn’t have to be good (it won’t be) or even readable (it won’t be).
Here’s how I made a several-thousand passage Twine with many more thousands of random connections between those passages:
First, I downloaded a public domain plain text version of Moby-Dick from the Gutenberg Archive. I chopped off all the boilerplate info and also deleted the Etymology and Extracts at the beginning of the novel, because I wanted readers to dive right in with the famous opening line.
Now, the Twine app itself doesn’t foster the editing of huge texts like Moby-Dick. And it doesn’t allow programmatic intervention—say, selecting random words, turning them into links, and routing them to random passages. But Twine is really just a graphical interface and compiler for a markup language called Twee. The fundamental elements of Twee are simple. Surround a word with double brackets, and the word turns into a link. For example, in Twee, [[this phrase]] would turn into a link, leading to a passage called “this phrase.” Or here, [[this phrase->new passage]] will have the text “this phrase” link to a new passage, clumsily called “new passage.” There are other compilers for Twee aside from the official Twine application. I use one called Tweego by Thomas Michael Edwards. With Tweego, you can write your Twee code in any text editor, and Tweego will convert it a playable HTML file. This means that you can take any text file, have a computer program algorithmically alter it with Twee markup, and generate a finished Twine project. So that’s what I did.
I wrote this Python program. It does a number of things, which follow.
First, it breaks Melville’s 1851 masterpiece into 2,463 individual Twine passages—basically every paragraph became its own standalone passage.
The program also gives each passage a title using the simplest method I could think of: the first passage is 0, the next is titled 1, the third is 2, and so on. That’s why there are numbers in each passage block in the screenshots above.
Next, the program uses the SpaCy natural language processing module to identify several named entities (i.e. proper nouns) and verbs in each passage.
Finally, the program links those nouns and verbs to one of the other over 2,463 passages by surrounding them with double brackets. This technique makes it a simple matter to direct links to a random passage. You just have Python pick a random number between 1 and 2,462 and direct the link there. Note that I excluded 0 (the title passage) from the random number generation, because that would have created an endless loop. The title passage only appears once, at the start.
After the Python has done all the work, I use Tweego on the command line to compile the actual Twine HTML file.
Sample Twee
You can check out the Python program that does the heavy-lifting on Github. But I thought people might also want to see what the Twee code looks like. It’s so simple. Here’s the first main passage. The double colons signify the passage title. So this passage is “1.” Then whenever you see double brackets, that’s a link to a different passage, which is also a number. For example, the name “Ishmael” becomes a link to passage #1626.
:: 1
Call me [[Ishmael->1626]]. [[Some years ago->2297]]--never mind how long precisely--having little or no money in my purse, and nothing particular to interest me on shore, I thought I would sail about a little and see the watery part of the world. It is a way I have of driving off the spleen and regulating the circulation. Whenever I find myself growing grim about the mouth; whenever it is a damp, drizzly [[November->526]] in my soul; whenever I find myself involuntarily pausing before coffin warehouses, and bringing up the rear of every funeral I meet; and especially whenever my hypos get such an upper hand of me, that it requires a strong moral principle to prevent me from deliberately stepping into the street, and methodically knocking people's hats off--then, I account it high time to get to sea as soon as I can. This is my substitute for pistol and ball. With a philosophical flourish Cato throws himself upon his sword; I quietly take to the ship. There is nothing surprising in this. If they but knew it, almost all men in their degree, some time or other, cherish very nearly the same feelings towards the ocean with me.
The links in this sample Twee code are different from the version of An End of Tarred Twine that I posted for NaNoGenMo and published on Itch. Because every time I run the Python script it creates an entirely new hypertext, with new links and paths through it. This what tickles me most about the project: anyone can take the source text and my Python program and generate their own version of An End of Tarred Twine. It reminds me of Aaron Reed’s recent novel Subcutanean, in which every printed version is different, algorithmically altered so that words, phrases, even entire scenes vary from one copy to the next—yet each version tells the fundamentally same story. In her review of Subcutanean, Emily Short suggests that the multitudinous machined variations fit the theme of the novel, of “the unknowable proliferation of motives and outcomes.”
Similarly, with An End of Tarred Twine we could have thousands of versions of the story, none alike. Just fork my code and make your own. A thousand different paths through Moby-Dick, none of them really Moby-Dick, but all of them monstrously “nameless, inscrutable, unearthly”—like the vengeful malice that drives Ahab himself to his ruin, dragging his beleaguered crew down with him.
The Infinite Catalog of Crushed Dreams (April 2020)
When you’re a college professor, you follow a different calendar from the rest of the grown-up world. There’s school and there’s summer, and that’s how you plot your time. Of course, a global pandemic wreaks havoc on this calendar. But usually, somewhere about now I stop thinking about the previous academic year and start looking ahead to the next one. My New Year begins on July 1, not January 1.
Since I’m closing the books on the 2019-2020 school year, I wanted to remind myself of all the projects I put out into the world during this time. Here in one place are all the critical-creative digital works I released in the past 12 months. I’ll write more about many of these projects later, so right now a blurb for each will have to suffice. Hopefully that’s enough to pique your interest…
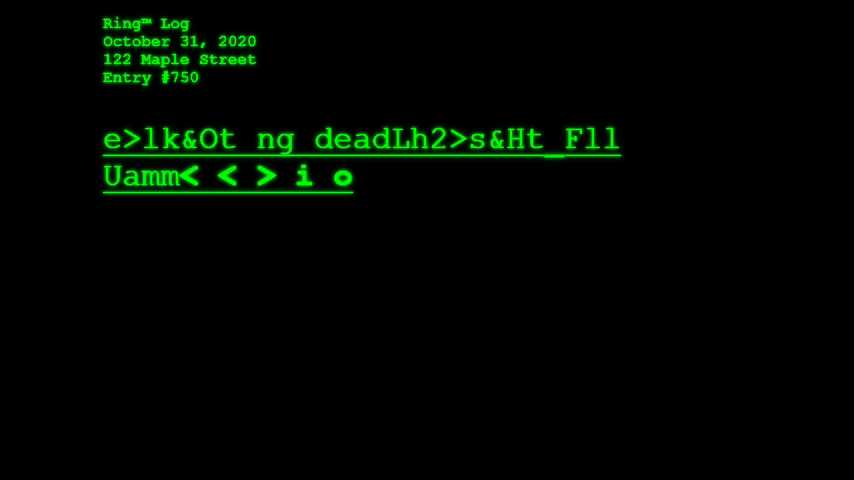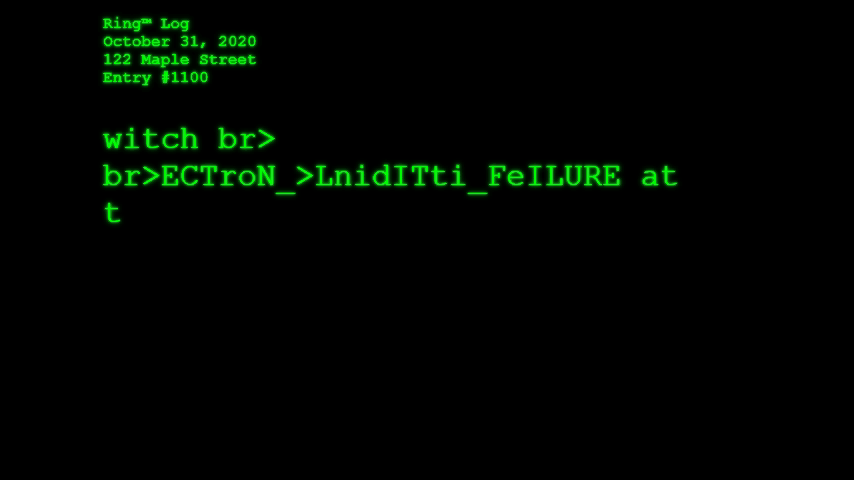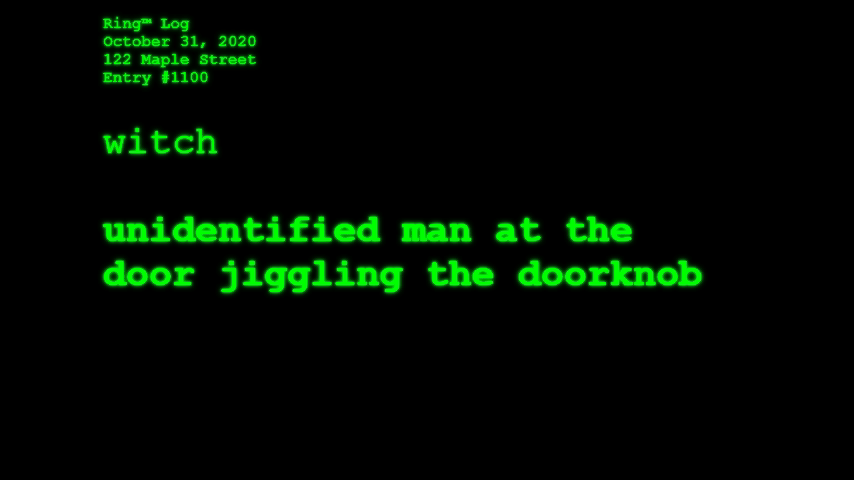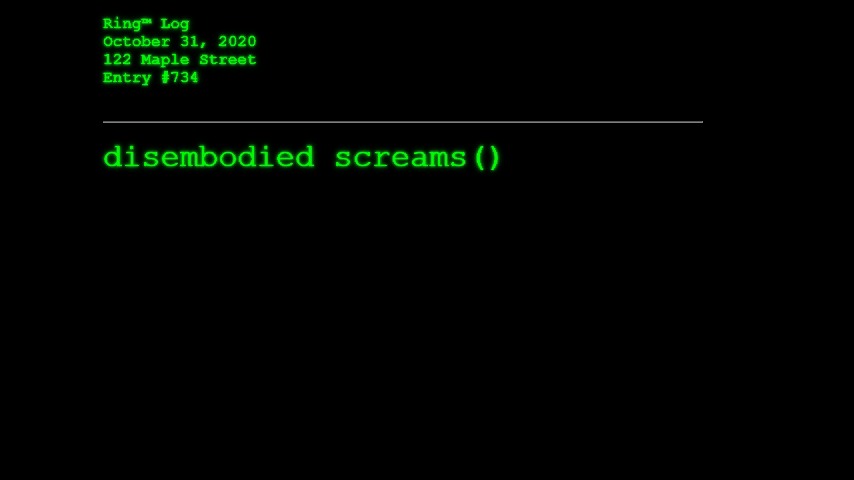
Ring™ Log (October 2019) – imagines what a Ring “smart” doorbell cam might see on a Halloween night
An End of Tarred Twine (November 2019) – a randomly generated hypertext version of Moby Dick in Twine, with 2,463 pages and 6,476 links, and utterly impossible to make sense of
Masks (December 2019) – a short hypertext narrative inspired by the Hong Kong protests
@BioDiversityPix (February 2020) – A bot that tweets random illustrations from the Biodiversity Heritage Library
Ring Pandemic Log (April 2020) – Using the same concept of Ring™ Log, this version imagines what a Ring camera might see during an early day of the coronavirus quarantine
You Gen #9 (May 2020) – the first chapter of a longer counterfactual interactive narrative about eugenics and gene-editing technology, set in the 1920s
Content Moderator Sim (June 2020) – A workplace horror game that puts you in the role of a subcontractor whose job is to keep your social media platform safe and respectable.
In general I was working in one of two modes for each project: procedural generation or interactive fiction. The former hopes to surprise readers with serendipitous juxtapositions and combinations, the latter hopes to entice readers with narrative impact. Whether I succeed at either is a question I’ll leave to others.
Over the weekend I launched Ring™ Log, which is simultaneously a critique of surveillance culture and a parody of machine vision in suburbia. In the interactive artist statement I call Ring™ Log an experiment in speculative surveillance.
“Speculative” in this context means what if?
What if Amazon’s Ring™ doorbell cams began integrating AI-powered object detection in order to identify, catalog, and report what the cameras “see” as they passively await for friends, neighbors, and strangers alike to visit your home? This is the question Ring™ Log asks. And, given the season (I write this on October 29, 2019), what would the cameras see and report on Halloween, when many of the figures that appear on your front stoop defy categorization?
I dive into the technical details and my inspirations in the artist statement, so no need to repeat myself here. I will add that I was very much inspired by an old Twilight Zone episode, even including several Easter Eggs to that effect. I was also inspired by the ridiculous posts I see on NextDoor, where paranoid neighbors routinely share Ring™ videos of “suspicious” visitors to their houses. Finally, I’m in debt to Everest Pipkin, whose work “What if Jupiter had turned into a Star” provided some of the underlying JavaScript effects for Ring™ Log. Everest’s work, like my own, appears with a permissive copyright license that allows for the reuse and modification of the code. Wouldn’t it be awesome if creative coders borrowed from Jupiter and Ring™ Log and made their own adaptations of these works, similar to what happened with Nick Montfort’s Taroko Gorge?
(Yeah, that’s a hint about what my students will be doing in my Electronic Literature course next semester!)
I don’t want to get into everything that’s broken with Twitter and has been for a long time. I don’t even especially want to get into that small slice of Twitter that was once important to me and is broken, which is its creative bot-making potential. I’ve written about bots already once or twice, back when I was more hopeful than I am these days.
I used to make bots for Twitter. At the peak I had around 50 bots running at once, some poetry, some prose, some political, and all strictly following Twitter’s terms of service. I was one of the bot good guys.
When I say I made bots “for Twitter” I mean that two ways. One, I made bots designed to post to Twitter, the way a tailor cuts a suit for a specific customer. I made bespoke bots. Artisanal bots, if you will.
But two, I made bots for Twitter, as in I provided free content for Twitter, as in I literally worked, for free, for Twitter. You could say it was mutual exploitation, but in the end, Twitter got the better deal. They got more avenues to serve ads and extract data, and I’m left with dozens of silly programs in Python and Node.js that no longer work and are basically worthless. I’m like the nerdy teen in some eighties John Hughes movie who went to the dance with the date of his dreams, and she leaves him listless on the gymnasium wall while she goes off dancing with just about everyone else, including the sadistic P.E. teacher.
But, hey, this isn’t a pity party! I said I wasn’t going to go into the way Twitter made it really difficult to make creative bots! But trust me, they did.
Instead, I thought it’d be fun to talk about all the other things that are broken, besides Twitter! And I’m going to use one of my old Twitter bots as an example. But, this is not about Twitter!
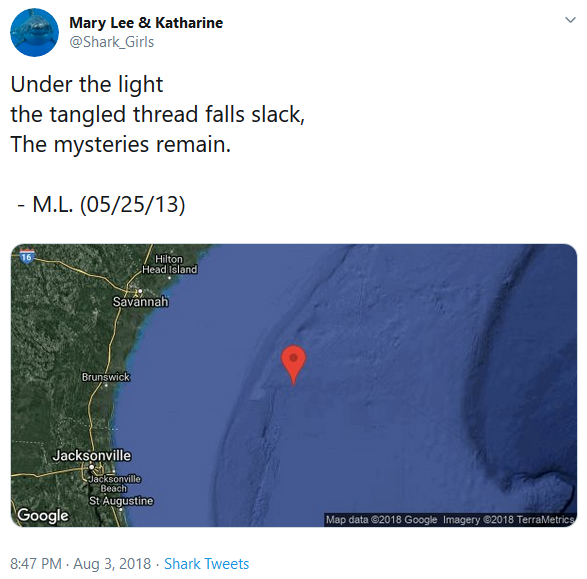
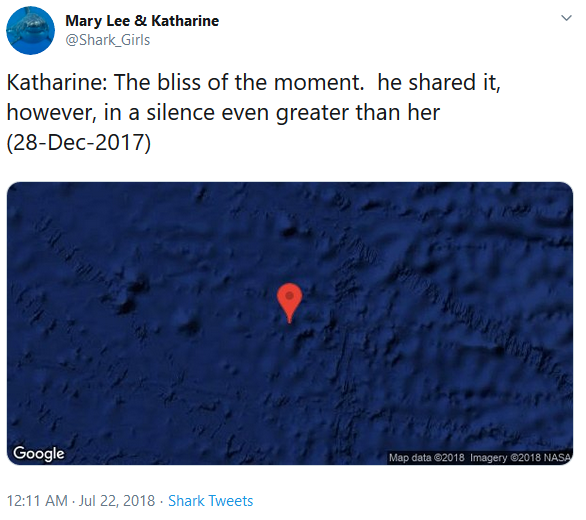
I’ve written before about how @shark_girls works. There are these great white sharks tagged with tracking devices. A few of these sharks became social media celebrities, though of course, not really, it was just some humans tweeting updates about the sharks. I thought, wouldn’t it be cool to give these sharks personalities and generate creative tweets that seemed to come directly from the sharks. So that’s what I did. I narrativized the raw data from these two great white sharks, Mary Lee and Katharine. Mary Lee tweets poetry, and shows where she was in the ocean when she “wrote” it. Katharine tweets prose, as if from a travel journal, and likewise includes a time, date, and location stamp:
To be clear: Mary Lee and Katharine are real sharks. They really are tagged with trackers that report their location whenever they surface longer than 90 seconds (the time needed to ping three satellites and triangulate their latitude and longitude). The locations and dates @shark_girls uses are lifted from the sharks’ tracking devices. You can see this data on the OCEARCH tracker, though my bot scrapes an undocumented backend server to get at it.
I’ve posted the code for the Mary Lee version of the bot. A whole lot of magic has to happen for the bot to work:
The sharks’ trackers have to be working
The sharks have to surface for longer than 90 seconds
The backdoor to the data has to stay open (OCEARCH could conceivably close it at any time, though they seem to have appreciated my creative use of their data)
The program queries the Google Maps API to get a satellite image of the pinged location
The program generates the poetic or prose passage that accompanies the tweet
The bot has to be properly authorized by Twitter
The @shark_girls bot hasn’t posted since August 20, 2018. That’s because it’s broken. To be specific: items 2, 4, 5, and 6 above no longer function. The bot is broken is so many ways that I’ll likely never fix it.
Let’s take it in reverse order.
The bot has to be properly authorized by Twitter
If I had just one or two Twitter bots, I could deal with fixing this. I need to associate a cellphone number with the bot. That’s supposed to ensure that it’s not a malicious bot, because for sure a Russian bot farm would never be able to register burner phone numbers with Twitter, no way, no how. But I’ve only got one phone number, and I already bounce it around the three or so bots that I have continued, in an uphill battle, to keep running. If I continue bouncing around the phone number, there’s a good chance Twitter could ban any bot associated with that number forever. The dynamic reminds a bit of the days in the early 2000s when the RIAA started suing what should have been its most valuable customers.
The program generates the poetic or prose passage that accompanies the tweet
Yeah, I could fix this easily too. The Mary Lee personality tweets poetry that’s a mashup of H.D.’s poetry. That system still works fine. The Katharine personality tweets from a remixed version of Virginia Woolf’s novel Night and Day. The bot reached the end of my remix. Katharine has no more passages to “write” right now. I could re-remix Night and Day, or select another novel and remix that. But I haven’t partially because of everything else that’s broken, partially because remixing a novel is a separate generative text problem, a rabbit hole I haven’t had time to go down lately. When I made the bot in 2015, it was Shark Week. Like is that a real holiday? I don’t know but the air was filled with shark energy. I was also living in a beach town in the southern Atlantic coast of Spain that summer. Spending hours making a bot about sharks just felt right. So I poured a lot of energy into the remix and into making the bot. It was a confluence of circumstances that created a drive that I no longer feel.
The program queries the Google Maps API to get an image of the pinged location
Nope, that’s not happening anymore. Google changed the terms of its map API, so that regular users like me can’t access it without handing over a credit card number. (API! That means Application Programming Interface. It’s essentially a portal that lets one program talk to another program, in this case how my bot talked to Google Maps and got some data out of it.) Google broke a gazillion creative, educational, and not-for-profit uses of its maps API when it started charging for access. Of course, what’s really crazy is that Google already charges us to use its services, though the invoice comes in the form of the mountains of data it extracts from us every day. There are open source alternatives to the Google Maps API that I technically could use for @shark_girls. But by this point, momentum is pushing me in the opposite direction. To just do…nothing.
The sharks have to surface for longer than 90 seconds
This is the least technical obstacle and totally out of my control. In a way, it’s a relief not to be able to do anything about this. The real Mary Lee and Katharine sharks have gone on radio silence. Mary Lee last surfaced and pinged the satellites over two years, though the OCEARCH team seems to believe she’s still out there.
Two years ago from today we got our last ping from @MaryLeeShark off the New Jersey coast. We miss hearing from her but we believe she is still out there visiting all her favorite spots. Celebrate her by snagging a Mary Lee tee https://t.co/QfJZIb3Ooipic.twitter.com/ZdPmzFeWFr
Likely she’s surfacing less than the 90 seconds required to contact the satellites. Possibly something has gone wrong with the tracker (which would hit item #1 in the above list of what could go wrong). There’s always a chance that Mary Lee could be dead, though I hate to even consider that possibility. But eventually, that will happen.
When to Stop Caring about What’s Broken
Earlier I said this post isn’t about Twitter. It’s not really about Google either, even though the advertising giant deserves to be on my shit list too. This isn’t about any single broken thing made by humans. If anything, it’s about the things the humans didn’t make: two great white sharks, swimming alone in a vast ocean. Humans didn’t make the oceans, but we sure are trying to break them.
When do you stop caring about the things that are broken? I could spend hours trying to fix the bot, and I could pretty much succeed. Even the lack of new data from the sharks isn’t a problem, as I could continue using historical data of their locations, which is still accessible.
I could fix the bot, but what would that accomplish?
Twitter, Google, every other Internet giant will still do their thing, which is to run ramshod over their users. Meanwhile, real sharks are a vulnerable species, thanks to hunting for shark fins, trophy hunting, bycatching by industrial fishing, and of course, climate change and the acidification of the oceans.
Caring for this bot, its continual upkeep and maintenance, accommodating the constantly shifting goal posts of the platforms that powered it, it’s all a distraction. I’ve made a deliberate decision not to care about this broken bot so that I can care about other things.
It’s broken in so many ways. Knowing when to stop caring is itself an act of caring. Because there are things out there you can fix, broken things you can repair. Care for them while you still can.
(Yikes. I think I just set myself up for another post, which is about what I am working on lately. Way to go Mark, creating more work for yourself.)
In 1965 the singer-songwriter Phil Ochs told an audience that “a protest song is a song that’s so specific you can’t mistake it for bullshit.” Ochs was introducing his anti-war anthem “I Ain’t Marching Anymore”—but also taking a jab at his occasional rival Bob Dylan, whose expressionistic lyrics by this time resembled Rimbaud more than Guthrie. The problem with Dylan, as far as Ochs was concerned, wasn’t that he had gone electric. It was that he wasn’t specific. You never really knew what the hell he was singing about. Meanwhile Ochs’ debut album in 1964 was an enthusiastic dash through fourteen very specific songs. The worst submarine disaster in U.S. history. The Cuban Missile Crisis. The murder of Emmett Till, the assassination of Medgar Evers. The sparsely produced album was called All the News That’s Fit to Sing, a play on the New York Times slogan “All the News That’s Fit to Print.” But more than mere parody, the title signals Ochs’ intention to best the newspaper at its own game, pronouncing and denouncing, clarifying and explaining, demanding and indicting the events of the day.
Ochs and the sixties protest movement are far removed from today’s world. There’s the sheer passage of time, of course. But there’s also been a half century of profound social and technological change, the greatest being the rise of computational culture. Networks, databases, videogames, social media. What, in this landscape, is the 21st century equivalent of a protest song? What is the modern version of a song so specific in its details, its condemnation, its anger, that it could not possibly be mistaken for bullshit?
One answer is the protest bot. A computer program that reveals the injustice and inequality of the world and imagines alternatives. A computer program that says who’s to praise and who’s to blame. A computer program that questions how, when, who and why. A computer program whose indictments are so specific you can’t mistake them for bullshit. A computer program that does all this automatically.
Bots are small automated programs that index websites, edit Wikipedia entries, spam users, scrape data from pages, launch denial of service attacks, and other assorted activities, both mundane and nefarious. On Twitter bots are mostly spam, but occasionally, they’re creative endeavors.
The bots in this small creative tribe that get the most attention—the @Horse_ebooks of the world (though @horse_ebooks would of course turn out later not to be a bot)—are surreal, absurd, purposeless for the sake of purposelessness. There is a bot canon forming, and it includes bots like @tofu_product, @TwoHeadlines, @everycolorbot, and @PowerVocabTweet. This emerging bot canon reminds me of the literary canon, because it values a certain kind of bot that generates a certain kind of tweet.
To build on this analogy to literature, I think of Repression and Recovery, Cary Nelson’s 1989 effort to reclaim a strain of American poetry excluded from traditional literary histories of the 20th century. The crux of Nelson’s argument is that there were dozens of progressive writers in the early to mid-20th century whose poems provided inconvenient counter-examples to what was considered “poetic” by mainstream culture. These poems have been left out of the canon because they were not “literary” enough. Nelson accuses literary critics of privileging poems that display ambivalence, inner anguish, and political indecision over ones that are openly polemical. Poems that draw clear distinctions between right and wrong, good and bad, justice and injustice are considered naïve by the academic establishment and deemed not worthy of analysis or teaching, and certainly not worthy of canonization. It’s Dylan over Ochs all over again.
A similar generalization might be made about what is valued in bots. But rather than ambivalence and anguish being the key markers of canon-worthy bots, it’s absurdism, comical juxtaposition, and an exhaustive sensibility (the idea that while a human cannot tweet every word or every unicode character, a machine can). Bots that don’t share these traits—say, a bot that tweets the names of toxic chemicals found in contaminated drinking water or tweets civilian deaths from drone attacks—are likely to be left out of the bot canon.
I don’t care much about the canon, except as a means to clue us in to what stands outside the canon. We should create and pay attention to bots that don’t fit the canon. And protest bots should be among these bots. We need bots that are not (or not merely) funny, random, or comprehensive. We need bots that are the algorithmic equivalent of the Wobblies’ Little Red Songbook, bots that fan the flames of discontent. We need bots of conviction.
Bots of Conviction
In his classic account of the public sphere, that realm of social life in which individuals discuss and shape public opinion, the German sociologist Jürgen Habermas describes a brief historical moment in the early 19th century in which the “journalism of conviction” thrived. The journalism of conviction did not simply compile notices as earlier newspapers had done; nor did the journalism of conviction seek to succeed purely commercially, serving the private interests of its owners or shareholders. Rather, the journalism of conviction was polemical, political, fervently debating the needs of society and the role of the state.
We may have lost the journalism of conviction, but it’s not too late to cultivate bots of conviction. I want to sketch out five characteristics of bots of conviction. I’ll name them here and describe each in more details. Bots of conviction are topical, data-based, cumulative, oppositional, and uncanny.
Topical. Asked where the ideas for his song came from, Ochs once pulled out a Newsweek and smiled, “From out of here.” Though probably apocryphal, the anecdote highlights the topical nature of protest songs, and by extension, protest bots. They are not about lost love or existential anguish. They are about the morning news—and the daily horrors that fail to make it into the news.
Data-based. Bots of conviction are based in data, which is another way of saying they don’t make this shit up. They draw from research, statistics, spreadsheets, databases. Bots have no subconscious, so any imagery they use should be taken literally. Protest bots give witness to the world we inhabit.
Cumulative. It is the nature of bots to do the same thing over and over again, with only slight variation. Repetition with a difference. Any single iteration may be interesting, but it is in the aggregate that a protest bot’s tweets attain power. The repetition builds on itself, the bot relentlessly riffing on its theme, unyielding and overwhelming, a pile-up of wreckage on our screens.
Oppositional. This is where the conviction comes in. Whereas the bot pantheon is populated by l’bot pour l’bot, protest bots take a stand. Society being what it is, this stance will likely be unpopular, perhaps even unnerving. Just as the most affecting protest songs made their audiences feel uncomfortable, bots of conviction challenge us to consider our own complicity in the wrongs of the world.
Uncanny. I’m using uncanny in the Freudian sense here, but without the psychodrama. The uncanny is the return of the repressed. The appearance of that which we had sought to keep hidden. I have to thank Zach Whalen for highlighting this last characteristic, which he frames in terms of visibility. Protests bots often reveal something that was hidden; or conversely, they might purposefully obscure something that had been in plain sight.
It’s one thing to talk about bots of conviction in theory. It’s quite another to talk about them in practice. What does a bot of conviction actually look like?
Consider master botmaker Darius Kazemi’s @TwoHeadlines. On one hand, the bot is most assuredly topical, as it functions by yoking two distinct news headlines into a single, usually comical headline. The bot is obviously data-driven too; the bot scrapes the headline data directly from Google News. On the other hand, @TwoHeadlines is neither cumulative nor oppositional. The bot posts at a moderate pace of once per hour, but while the individual tweets accumulate they do not build up to something. There is no theme the algorithm compulsively revisits. Each tweet is a one-off one-liner. Most critically, though, the bot takes no stance. @TwoHeadlines reflects the news, but it does not reflect on the news. It may very well be Darius’ best bot, but it lacks all conviction.
What about another recent bot, Chuck Rybak’s @TheHigherDead? [Update: @TheHigherDead account has disappeared.] Chuck lampoons utopian ed-tech talk in higher education, putting jargon such as “disrupt” and “innovate” in the mouths of zombies. Chuck uses the affordances of the Twitter bio to sneak in a link to the Clayton Christensen Institute. Christensen is the Harvard Business School professor who popularized terms like “disruptive innovation” and “hybrid innovation”—ideas that when applied to K12 or higher ed appear to be little more than neo-liberal efforts to pare down labor costs and disempower faculty. When these ideas are actually put into action, we get the current crisis in the University of Wisconsin system, where Chuck teaches. @TheHigherDead is oppositional and uncanny, in the way that anything having to do with zombies is uncanny. It’s even topical, but is it a protest bot? It’s parody, but its data is too eclectic to be considered data-based. If @TheHigherDead mined actual news accounts and ed-tech blogs for more jargon and these phrases showed up in the tweets, the bot would rise beyond parody to protest.
@TwoHeadlines and @TheHigherDead are not protest bots, but then, they’re not supposed to be. I am unfairly applying my own criteria to it, but only to illustrate what I mean by the terms topical, data-based, cumulative, oppositional, and uncanny. It’s worth testing this criteria against another bot: Zach Whalen’s @ClearCongress. This bot retweets members of Congress after redacting a portion of the original tweet. The length of the redaction corresponds to the current congressional approval rate; the lower the approval rating, the more characters are blocked.
MT █ SENJOHNTHUNE: ▓▓▓▓▒ ▒▓▓▓▓▓▓▒ ▓▓▒▓ ▓▓▓▓ ▓▓▓▓▓CKET WITH NEW ▒▓▓▓▓▒ ▓▓▓▓▓▒▓▓▓▒▓ @▒▓▒▓▓▒▒ ▓▒▓▓▓▓▒▓▓▓▓▓▓▒▒▓▒▓▓▓▓▒
Assuming our senators and representatives post about current news and policies, the bot is topical. It is also data-driven, doubly-so, since it pulls from congressional accounts and up-to-date polling data from the Huffington Post. The bot is cumulative as well. Scrolling through the timeline you face an indecipherable wall of ▒▒▒▒ and ▓▓▓▓, a visual effect intensified by Twitter’s infinite scrolling. By obscuring text, the bot plays in the register of the visible and invisible—the uncanny. And despite not saying anything legible, @ClearCongress has something to say. It’s an oppositional bot, thematizing the disconnect between the will of the people and the rulers of the land. At the same time, the bot suggests that Congress has replaced substance with white noise, that all senators and representatives end up sounding the same, regardless of their politics, and that, most damning of all, Congress is ineffectual, all but useless.
Another illustrative protest bot likewise uses Congress as its target. Ed Summers’ @congressedits tweets whenever anonymous edits are made to Wikipedia from IP addresses associated with the U.S. Congress. [Update: Ed has removed @congressedits from Twitter, but the bot now posts intermittently on Mastodon.] In other words, whenever anyone in Congress—likely Congressional staffers, but conceivably representatives and senators themselves—attempts to edit a Wikipedia article anonymously, the bot flags that edit and calls attention to it. This is the uncanny hallmark of @congressedits: making visible that which others seek to hide, bringing transparency to a key source of information online, and in the process highlighting the subjective nature of knowledge production in online spaces. @congressedits operates in near real-time; these are not historical revisions to Wikipedia, they are edits that are happening right now. The bot is obviously data-driven too. Summers’ bot responds to data from Wikipedia’s API, but it also send us, the readers, directly to the diff page of that edit, where we can clearly see the specific changes made to the page. It turns out that many of the revisions are copyedits—fixing punctuation, spelling, or grammar. This revelation undercuts our initial cynical assumption that every anonymous Wikipedia edit from Congress is ideologically-driven. Yet it also supports the message of @ClearCongress. Congress is so useless that they have nothing better to do than fix comma splices on Wikipedia? Finally, there’s one more layer of @congressedits to mention, which speaks again to the issue of transparency. Summers has shared the code on Github, making it possible for others to programmatically develop customized clones, and there are dozens of such bots now, tracking changes to Wikipedia.
There are not many bots of conviction, but they are possible, as @ClearCongress and @congress-edits demonstrate. I’ve attempted to make several agit-bots myself, though when I started, I hadn’t thought through the five characteristics I describe above. In a very real sense, my theory about bots as a form of civic engagement grew out of my own creative practice.
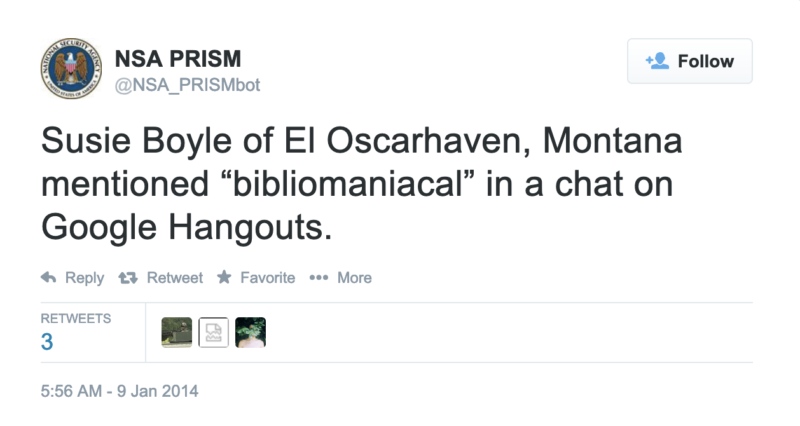
I made my first protest bot in the wake of the Snowden revelations about PRISM, the NSA’s downstream surveillance program. I created @NSA_PRISMbot. The bot is an experiment in speculative surveillance, imagining the kind of useless information the NSA might distill from its invasive data-gathering:
@NSA_PRISMbot is topical, of course, rooted in specificity. The Internet companies the bot names are the same services identified on the infamous NSA PowerPoint slide. When Microsoft later changed the name of SkyDrive to OneDrive, the bot even reflected that change. Similarly, @NSA_PRISMbot will occasionally flag (fake) social media activity using the list of keywords and search terms the Department of Homeland Security tracks on social media.
Any single tweet of NSA_PRISMbot may be clever, with humorous juxtapositions at work. But the real power of the bot is the way the individual invasions of privacy accumulate. The bot is like a devotional exercise, in which repetition is an attempt at deeper understanding.
I followed up @NSA_PRISMbot with @NSA_AllStars, whose satirical profile notes that it “honors the heroes behind @NSA_PRISMbot, who keep us safe from the bad guys.” This bot builds on the revelations that NSA workers and subcontractors had spied on their own friends and family.
The code of @nsa_allstars
The bot names names, including the various divisions of the NSA and the companies that are documented subcontractors for the NSA.
A Bot Canon of Anger
While motivated by conviction, neither of these NSA bots are explicit in their outrage. So here’s an angry protest bot, one I made out of raw emotion, a bitter compound of fury and despair. On May 23, 2014, Elliot Rodger killed six people and injured fourteen more near the campus of UC-Santa Barbara. In addition to my own anger I was moved by the grief of my friends, several of whom teach at UC Santa Barbara. It was Alan Liu’s heartfelt act of public bereavement that most clearly articulated what I sought in this protest bot:
What is the literary canon of anger that must back up that of consolation to give full-throated voice to #NotOneMore? →
Whereas Alan turns toward literature for a full-throated cry of anger, I turned toward algorithmic culture, to the margins of the computational world. I created a bot of consolation and conviction that—to paraphrase Phil Ochs in “When I’m Gone”—tweets louder than the guns.
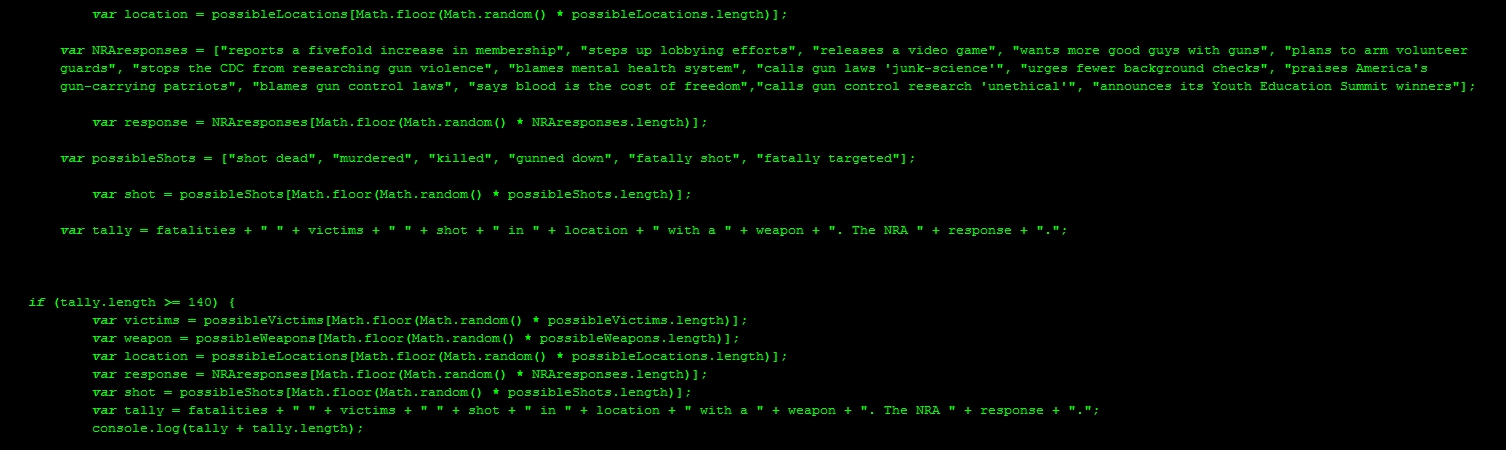
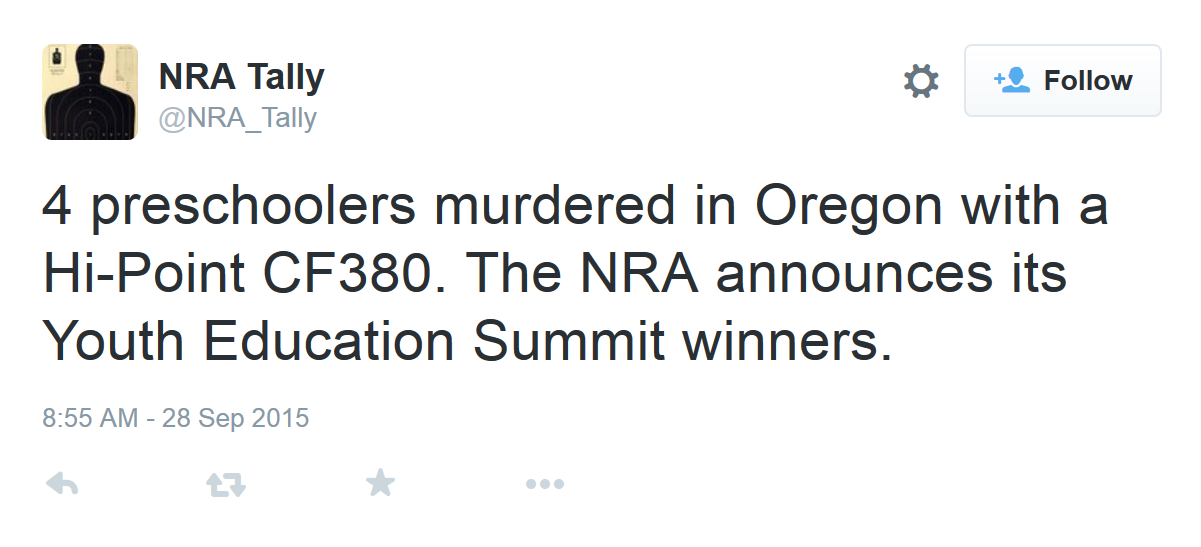
The bot I made is @NRA_Tally. It posts imagined headlines about mass shootings, followed by a fictionalized but believable response from the NRA:
@NRA_Tally
The bot is topical, grievously so. More critically, you cannot mistake it for bullshit. The bot is data-driven, populated with statistics from a database of over thirty years of mass shootings in the U.S. Here are the individual elements that make up the template of every @NRA_Tally tweet:
A number. The bot selects a random number between 4 (the threshold for what the FBI defines as mass murder) and 35 (just above the Virginia Tech massacre, the worst mass shooting in American history).
The victims. The victims are generalizations drawn from the historical record. Sadly this means teachers, college students, elementary school children.
Location. The city and state names have all been sites of mass shootings. I had considered either seeding the location with a huge list of cities or simply generating fake city names (which is what @NSA_PRISMbot does). I decided against these approaches, however, because I was determined to have @NRA_Tally act as a witness to real crimes.
Firearm. The bot randomly selects the deadly weapon from an array of 64 items, all handguns or rifles that have been used in a mass shooting in the United States. An incredible 75% of the weapons fired in mass shootings have been purchased legally, the killers abiding by existing gun regulations. Many of the guns were equipped with high-capacity magazines, again, purchased legally. The 140-character constraint of Twitter means some weapon names have been shortened, dropping, for example the words “semiautomatic” or “sawed-off.”
Response. This is a statement from the NRA in the form of a press release. Every possible response mirrors actual rhetorical moves the NRA has made after previous mass shootings. There are currently 14 stock responses, but the NRA has undoubtedly issued other statements of scapegoating and misdirection. @NRA_Tally is participatory in the sense that you can contribute to its database of responses. Simply submit a generalized yet documented response and I will incorporate it into the code.
@NRA_Tally is terrifying and unsettling, posing scenarios that go beyond the plausible into the realm of the super-real. It is an oppositional bot on several levels. It is obviously antagonistic toward the NRA. It is oppositional toward false claims that “guns don’t kill people,” purposefully foregrounding weapons over killers. It is even oppositional to social media itself, challenging the logic of following and retweeting. Who would be comfortable seeing such tragedies in their timeline on an hourly basis? Who would dare to retweet something that could be taken as legitimate news, thereby spreading unnecessary rumors and lies?
Protest Bots as Tactical Media
A friend who saw an early version of @NRA_Tally expressed unease about it, wondering whether or not the bot would be gratuitous. The bot canon is full of playful bots that are nonsensical and superfluous. @NRA_Tally is neither playful nor nonsensical, but is it superfluous?
No, it is not. @NRA_Tally, like all protest bots, is an example of tactical media. Rita Raley, another friend at UCSB, literally wrote the book on tactical media, a form of media activism that engages in a “micropolitics of disruption, intervention, and education.” Tactical media targets “the next five minutes” rather than some far off revolutionary goal. As tactical media, protest bots do not offer solutions. Instead they create messy moments that destabilize narratives, perspectives, and events.
How might such destabilization work in the case of @NRA_Tally?
As Salon points out, it is the NRA’s strategy—this is a long term policy rather than a tactical maneuver—to shut down debate by accusing anyone who talks about gun control as politicizing the victims’ death. A bot of conviction, however, cannot be shut down by such ironic accusations. A protest bot cannot be accused of dishonoring the victims when there are no actual victims. As the bot inexorably piles on headline after headline, it becomes clear that the center of gravity of each tweet is the name of the weapon itself. The bot is not about victims. It is about guns and the organization that makes such preventable crimes possible.
The public debate about gun violence is severely limited. This bot attempts to unsettle it, just for a minute. And, because this is a bot that doesn’t back down and cannot cower and will tweet for as long as I let it, it has many of these minutes to make use of. Bots of conviction are also bots of persistence.
Adorno once said that it is the role of the cultural critic to present society a bill it cannot pay. Adorno would not have good things to say about computational culture, let alone social media. But even he might appreciate that not only can protest bots present society a bill it cannot pay, they can do so at the rate of once every two minutes. They do not bullshit around.
An earlier version of this essay on Protest Bots can be found on Medium.
I put “deep” in scare quotes but really, all three words should have quotes around them—”deep” “textual” “hacks”—because all three are contested, unstable terms. The workshop is hands-on, but I imagine we’ll have a chance to talk about the more theoretical concerns of hacking texts. The workshop is inspired by an assignment from my Hacking, Remixing, and Design class at Davidson, where I challenge students to create works of literary deformance that are complex, intense, connected, and shareable. (Hey, look, more contested terms! Or at the very least, ambiguous terms.)
We don’t have much time for this workshop. In this kind of constrained setting I’ve found it helps to begin with templates, rather than creating something from scratch. I’ve also decided we’ll steer clear of Python—what I’ve been using recently for my own literary deformances—and work instead in the browser. That means Javascript. Say what you want about Javascript but you can’t deny that Daniel Howe’s RiTA library is a powerful tool for algorithmic literary play. But we don’t even need RiTA for our first “hack”:
What’s great about “Taroko Gorge” is how easy it is to hack. Dozens have done it, including me. All you need is a browser and a text editor. Nick never explicitly released the code of “Taroko Gorge” under a free software license, but it’s readily available to anyone who views the HTML source of the poem’s web page. Lean and elegantly coded, with self-evident algorithms and a clearly demarcated word list, the endless poem lends itself to reappropriation. Simply altering the word list (the paradigmatic axis) creates an entirely different randomly generated poem, while the underlying sentence structure (the syntagmatic axis) remains the same.
The next textual hack template we’ll work with is my own:
This little generator is essentially half of @_LostBuoy_. It generates Markov chains from a source text, in this case, Moby-Dick. What’s a Markov chain? It’s a probabilistic chain of n-grams, that is, words. The algorithm examines a source text and figures out which word or words are likely to follow another word or other words. The “n” in n-gram refers to the number of words you want the algorithm to look for. For example, a bi-gram Markov chain calculates which pair of words are likely to follow another pair of words. Using this technique, you can string together sentences, paragraphs, or entire novels. The higher the “n” the more likely the output is to resemble the source material—and by extension, sensible English. Whereas “Taroko Gorge” plays with the paradigmatic axis (substitution), Markov chains play along the syntagmatic axis (sentence structure). There are various ways to calculate Markov chains; creating a Markov chain generator is even a common Intro to Computer Science assignment. I didn’t build my own generator, and you don’t have to either. I use RiTA, a Javascript (and Processing) library that works in the browser, with helpful documentation.
The final deformance is a web-based version of the popular @JustToSayBot:
And I have a challenge here: thanks to the 140-character limit of Twitter, the bot version of this poem is missing the middle verse. The web has no such limit, of course, so nothing is stopping workshop participants from adding the missing verse. Such a restorative act of hacking would be, in a sense, a de-deformance, that is, making my original deformance less deformative, more like the original.
The Electronic Literature Organization’s annual conference was last week in Milwaukee. I hated to miss it, but I hated even more the idea of missing my kids’ last days of school here in Madrid, where we’ve been since January.
If I had been at the ELO conference, I’d have no doubt talked about bots. I thought I already said everything I had to say about these small autonomous programs that generate text and images on social media, but like a bot, I just can’t stop.
Here, then, is one more modest attempt to theorize bots—and by extension other forms of computational media. The tl;dr version is that there are two archetypes of bots: closed bots and green bots. And each of these archetypes comes with an array of associated characteristics that deepen our understanding of digital media. Continue reading “Closed Bots and Green Bots Two Archetypes of Computational Media“→
Mark Z. Danielewski’s House of Leaves is a massive novel about, among other things, a house that is bigger on the inside than the outside. Walt Whitman’s Leaves of Grass is a collection of poems about, among other things, the expansiveness of America itself.
What happens when these two works are remixed with each other? It’s not such an odd question. Though separated by nearly a century, they share many of the same concerns. Multitudes. Contradictions. Obsession. Physical impossibilities. Even an awareness of their own lives as textual objects.
To explore these connections between House of Leaves and Leaves of Grass I have created House of Leaves of Grass, a poem (like Leaves of Grass) that is for all practical purposes boundless (like the house on Ash Tree Lane in House of Leaves). Or rather, it is bounded on an order of magnitude that makes it untraversable in its entirety. The number of stanzas (from stanza, the Italian word for “room”) approximates the number of cells in the human body, around 100 trillion. And yet the container for this text is a mere 24K. Continue reading “no life no life no life no life: the 100,000,000,000,000 stanzas of House of Leaves of Grass”→









{kind=link}